Senior Distinguished Research Scientist, NVIDIA
Docent, Aalto University
Google Scholar
NVIDIA
Porkkalankatu 1, 5th floor
00180 Helsinki
Finland
taila
| |
Timo Aila, PhD
Senior Distinguished Research Scientist, NVIDIA Docent, Aalto University Google Scholar NVIDIA Porkkalankatu 1, 5th floor 00180 Helsinki Finland taila |
My current research is at the intersection of neural network architectures, machine learning, and computer graphics.
I have a particular focus on generative modeling.
Publications |
Expand all Collapse all |
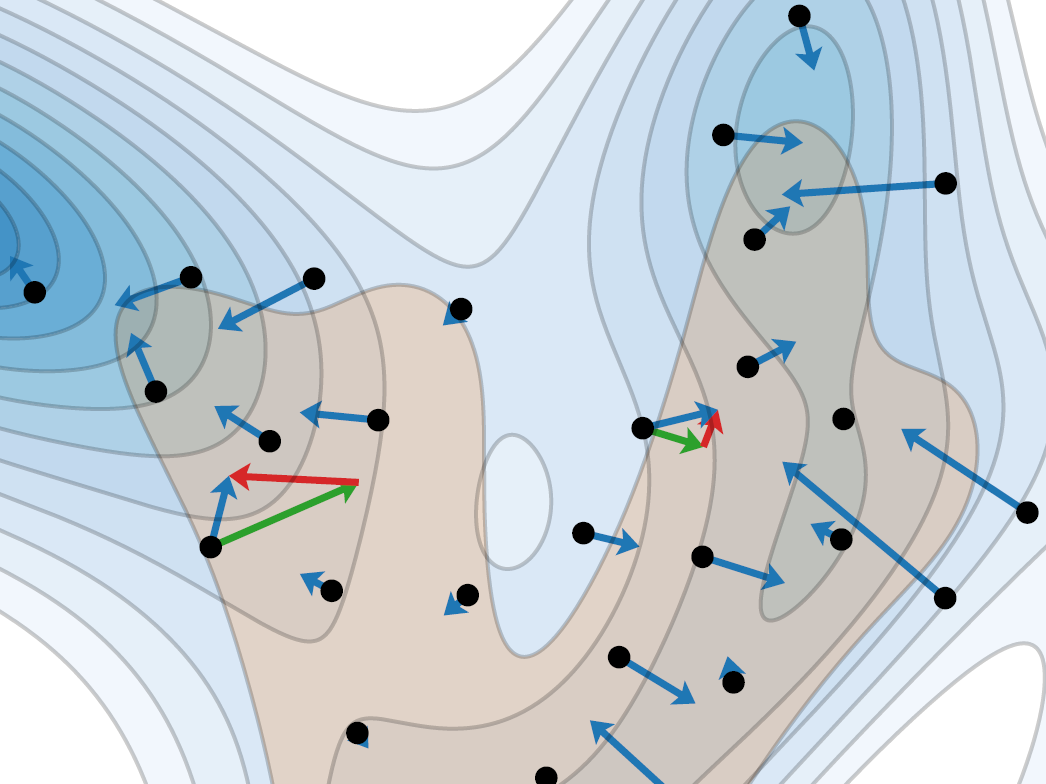
The primary axes of interest in image-generating diffusion models are image quality, the amount of variation in the results, and how well the results align with a given condition, e.g., a class label or a text prompt. The popular classifier-free guidance approach uses an unconditional model to guide a conditional model, leading to simultaneously better prompt alignment and higher-quality images at the cost of reduced variation. These effects seem inherently entangled, and thus hard to control. We make the surprising observation that it is possible to obtain disentangled control over image quality without compromising the amount of variation by guiding generation using a smaller, less-trained version of the model itself rather than an unconditional model. This leads to significant improvements in ImageNet generation, setting record FIDs of 1.01 for 64x64 and 1.25 for 512x512, using publicly available networks. Furthermore, the method is also applicable to unconditional diffusion models, drastically improving their quality.
@inproceedings{Karras2024autoguidance,
author = {Tero Karras and Miika Aittala and Tuomas Kynk\"a\"anniemi and Jaakko Lehtinen and Timo Aila and Samuli Laine},
title = {Guiding a Diffusion Model with a Bad Version of Itself},
booktitle = {Proc. NeurIPS},
year = {2024},
}
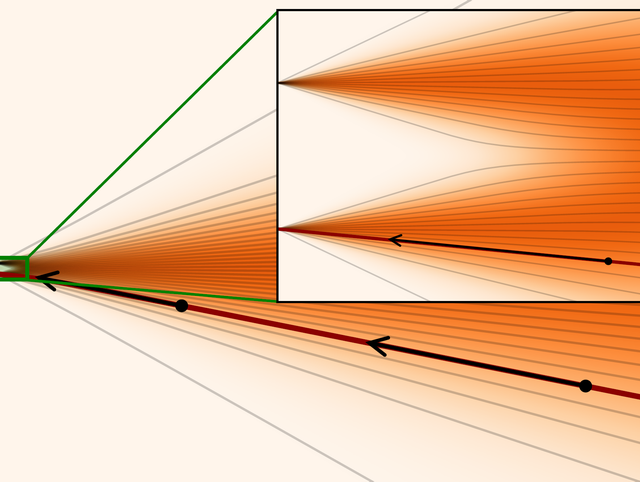
AbstractGuidance is a crucial technique for extracting the best performance out of image-generating diffusion models. Traditionally, a constant guidance weight has been applied throughout the sampling chain of an image. We show that guidance is clearly harmful toward the beginning of the chain (high noise levels), largely unnecessary toward the end (low noise levels), and only beneficial in the middle. We thus restrict it to a specific range of noise levels, improving both the inference speed and result quality. This limited guidance interval improves the record FID in ImageNet-512 significantly, from 1.81 to 1.40. We show that it is quantitatively and qualitatively beneficial across different sampler parameters, network architectures, and datasets, including the large-scale setting of Stable Diffusion XL. We thus suggest exposing the guidance interval as a hyperparameter in all diffusion models that use guidance.
@inproceedings{Kynkaanniemi2024guidance,
author = {Tuomas Kynk\"a\"anniemi and Miika Aittala and Tero Karras and Samuli Laine and Timo Aila and Jaakko Lehtinen},
title = {Applying Guidance in a Limited Interval Improves Sample and Distribution Quality in Diffusion Models},
booktitle = {Proc. NeurIPS},
year = {2024},
}
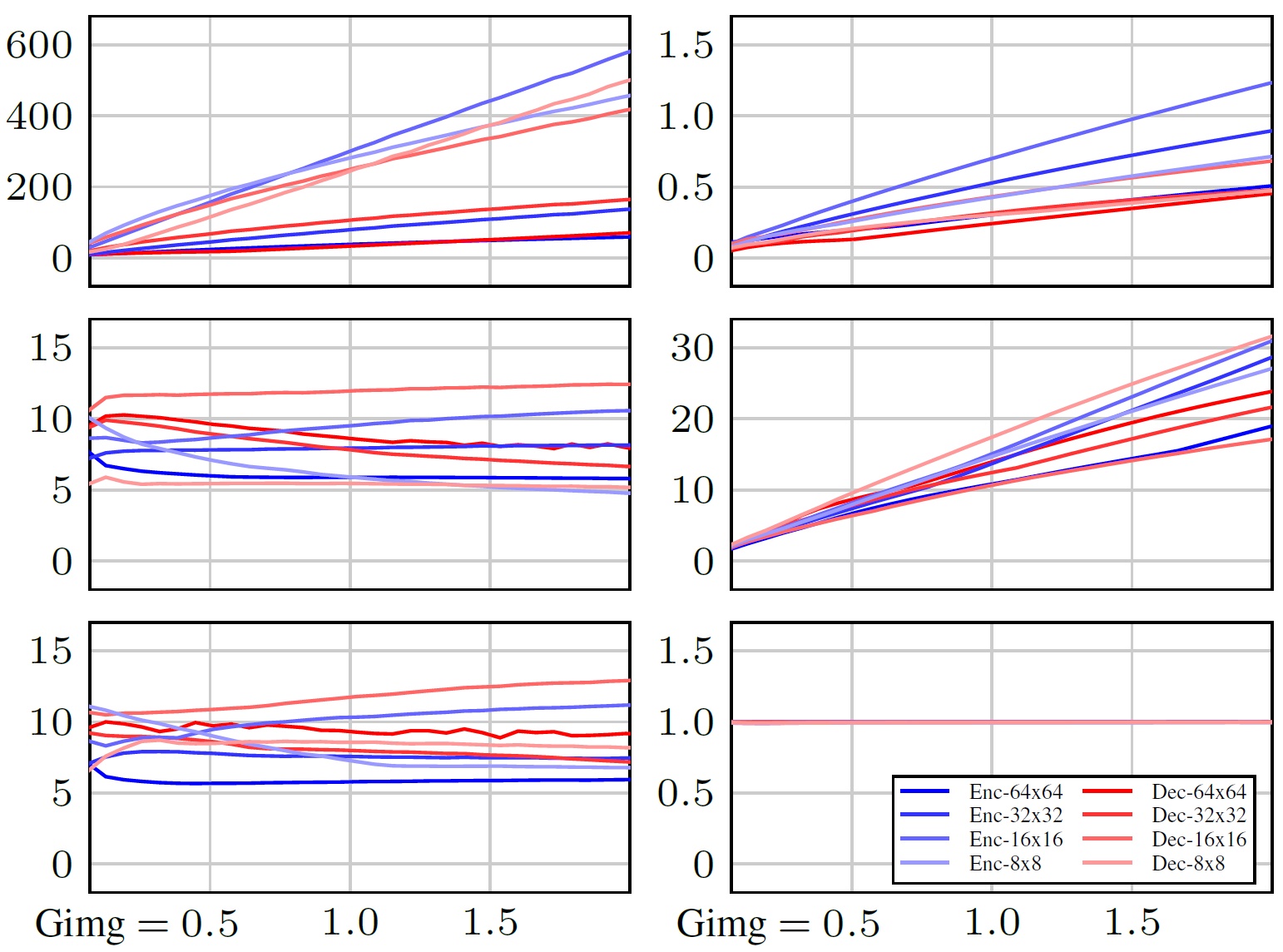
AbstractDiffusion models currently dominate the field of data-driven image synthesis with their unparalleled scaling to large datasets. In this paper, we identify and rectify several causes for uneven and ineffective training in the popular ADM diffusion model architecture, without altering its high-level structure. Observing uncontrolled magnitude changes and imbalances in both the network activations and weights over the course of training, we redesign the network layers to preserve activation, weight, and update magnitudes on expectation. We find that systematic application of this philosophy eliminates the observed drifts and imbalances, resulting in considerably better networks at equal computational complexity. Our modifications improve the previous record FID of 2.41 in ImageNet-512 synthesis to 1.81, achieved using fast deterministic sampling. As an independent contribution, we present a method for setting the exponential moving average (EMA) parameters post-hoc, i.e., after completing the training run. This allows precise tuning of EMA length without the cost of performing several training runs, and reveals its surprising interactions with network architecture, training time, and guidance.
@incollection{Karras2024,
author = {Tero Karras and Miika Aittala and Jaakko Lehtinen and Janne Hellsten and Timo Aila and Samuli Laine},
title = {Analyzing and Improving the Training Dynamics of Diffusion Models},
booktitle = {Proc. CVPR},
year = {2024}
}
AbstractText-to-image synthesis has recently seen significant progress thanks to large pretrained language models, large-scale training data, and the introduction of scalable model families such as diffusion and autoregressive models. However, the best-performing models require iterative evaluation to generate a single sample. In contrast, generative adversarial networks (GANs) only need a single forward pass. They are thus much faster, but they currently remain far behind the state-of-the-art in large-scale text-to-image synthesis. This paper aims to identify the necessary steps to regain competitiveness. Our proposed model, StyleGAN-T, addresses the specific requirements of large-scale text-to-image synthesis, such as large capacity, stable training on diverse datasets, strong text alignment, and controllable variation vs. text alignment tradeoff. StyleGAN-T significantly improves over previous GANs and outperforms distilled diffusion models - the previous state-of-the-art in fast text-to-image synthesis - in terms of sample quality and speed.
@incollection{Sauer2023,
author = {Axel Sauer and Tero Karras and Samuli Laine and Andreas Geiger and Timo Aila},
title = {{StyleGAN-T}: Unlocking the Power of {GAN}s for Fast Large-Scale Text-to-Image Synthesis},
booktitle = {Proc. ICML},
year = {2023}
}
AbstractFréchet Inception Distance (FID) is the primary metric for ranking models in data-driven generative modeling. While remarkably successful, the metric is known to sometimes disagree with human judgement. We investigate a root cause of these discrepancies, and visualize what FID “looks at” in generated images. We show that the feature space that FID is (typically) computed in is so close to the ImageNet classifications that aligning the histograms of Top-N classifications between sets of generated and real images can reduce FID substantially -- without actually improving the quality of results. Thus we conclude that FID is prone to intentional or accidental distortions. As a practical example of an accidental distortion, we discuss a case where an ImageNet pre-trained FastGAN achieves a FID comparable to StyleGAN2, while being worse in terms of human evaluation.
@incollection{Kynkaanniemi2023,
author = {Tuomas Tuomas Kynk\"a\"anniemi and Tero Karras and Miika Aittala and Timo Aila and Jaakko Lehtinen},
title = {The Role of ImageNet Classes in Fr\'echet Inception Distances},
booktitle = {Proc. ICLR},
year = {2023}
}
AbstractWe argue that the theory and practice of diffusion-based generative models are currently unnecessarily convoluted and seek to remedy the situation by presenting a design space that clearly separates the concrete design choices. This lets us identify several changes to both the sampling and training processes, as well as preconditioning of the score networks. Together, our improvements yield new state-of-the-art FID of 1.79 for CIFAR-10 in a class-conditional setting and 1.97 in an unconditional setting, with much faster sampling (35 network evaluations per image) than prior designs. To further demonstrate their modular nature, we show that our design changes dramatically improve both the efficiency and quality obtainable with pre-trained score networks from previous work, including improving the FID of a previously trained ImageNet-64 model from 2.07 to near-SOTA 1.55, and after re-training with our proposed improvements to a new SOTA of 1.36.
@incollection{Karras2022elucidating,
author = {Tero Karras and Miika Aittala and Timo Aila and Samuli Laine},
title = {Elucidating the Design Space of Diffusion-Based Generative Models},
booktitle = {Advances in Neural Information Processing Systems 35 (proc. NeurIPS 2022)},
year = {2022}
}
AbstractLarge-scale diffusion-based generative models have led to breakthroughs in text-conditioned high-resolution image synthesis. Starting from random noise, such text-to-image diffusion models gradually synthesize images in an iterative fashion while conditioning on text prompts. We find that their synthesis behavior qualitatively changes throughout this process: Early in sampling, generation strongly relies on the text prompt to generate text-aligned content, while later, the text conditioning is almost entirely ignored. This suggests that sharing model parameters throughout the entire generation process may not be ideal. Therefore, in contrast to existing works, we propose to train an ensemble of text-to-image diffusion models specialized for different synthesis stages. To maintain training efficiency, we initially train a single model, which is then split into specialized models that are trained for the specific stages of the iterative generation process. Our ensemble of diffusion models, called eDiff-I, results in improved text alignment while maintaining the same inference computation cost and preserving high visual quality, outperforming previous large-scale text-to-image diffusion models on the standard benchmark. In addition, we train our model to exploit a variety of embeddings for conditioning, including the T5 text, CLIP text, and CLIP image embeddings. We show that these different embeddings lead to different behaviors. Notably, the CLIP image embedding allows an intuitive way of transferring the style of a reference image to the target text-to-image output. Lastly, we show a technique that enables eDiff-I's "paint-with-words" capability. A user can select the word in the input text and paint it in a canvas to control the output, which is very handy for crafting the desired image in mind. The project page is available at https://deepimagination.cc/eDiff-I/
@article{balaji2022eDiff-I,
title = {{eDiff-I}: {T}ext-to-Image Diffusion Models with Ensemble of Expert Denoisers},
author = {Yogesh Balaji and Seungjun Nah and Xun Huang and Arash Vahdat and Jiaming Song and Karsten Kreis and Miika Aittala and Timo Aila and Samuli Laine and Bryan Catanzaro and Tero Karras and Ming-Yu Liu},
journal = {arXiv preprint arXiv:2211.01324},
year = {2022}
}
AbstractWe present a video generation model that accurately reproduces object motion, changes in camera viewpoint, and new content that arises over time. Existing video generation methods often fail to produce new content as a function of time while maintaining consistencies expected in real environments, such as plausible dynamics and object persistence. A common failure case is for content to never change due to over-reliance on inductive biases to provide temporal consistency, such as a single latent code that dictates content for the entire video. On the other extreme, without long-term consistency, generated videos may morph unrealistically between different scenes. To address these limitations, we prioritize the time axis by redesigning the temporal latent representation and learning long-term consistency from data by training on longer videos. To this end, we leverage a two-phase training strategy, where we separately train using longer videos at a low resolution and shorter videos at a high resolution. To evaluate the capabilities of our model, we introduce two new benchmark datasets with explicit focus on long-term temporal dynamics.
@incollection{Brooks2022,
author = {Tim Brooks and Janne Hellsten and Miika Aittala and Ting-Chun Wang and Timo Aila and Jaakko Lehtinen and Ming-Yu Liu and Alexei A. Efros and Tero Karras},
title = {Generating Long Videos of Dynamic Scenes},
booktitle = {Advances in Neural Information Processing Systems 35 (proc. NeurIPS 2022)},
year = {2022}
}
AbstractTime-lapse image sequences offer visually compelling insights into dynamic processes that are too slow to observe in real time. However, playing a long time-lapse sequence back as a video often results in distracting flicker due to random effects, such as weather, as well as cyclic effects, such as the day-night cycle. We introduce the problem of disentangling time-lapse sequences in a way that allows separate, after-the-fact control of overall trends, cyclic effects, and random effects in the images, and describe a technique based on data-driven generative models that achieves this goal. This enables us to "re-render" the sequences in ways that would not be possible with the input images alone. For example, we can stabilize a long sequence to focus on plant growth over many months, under selectable, consistent weather.
Our approach is based on Generative Adversarial Networks (GAN) that are conditioned with the time coordinate of the time-lapse sequence. Our architecture and training procedure are designed so that the networks learn to model random variations, such as weather, using the GAN's latent space, and to disentangle overall trends and cyclic variations by feeding the conditioning time label to the model using Fourier features with specific frequencies.
We show that our models are robust to defects in the training data, enabling us to amend some of the practical difficulties in capturing long time-lapse sequences, such as temporary occlusions, uneven frame spacing, and missing frames.
@article{Harkonen2022tlgan,
author = {Erik H\"ark\"onen and Miika Aittala and Tuomas Kynk\"a\"anniemi and Samuli Laine and Timo Aila and Jaakko Lehtinen},
title = {Disentangling Random and Cyclic Effects in Time-Lapse Sequences},
journal = {{ACM} Transactions on Graphics},
volume = {41},
number = {4},
year = {2022},
}
AbstractWe observe that despite their hierarchical convolutional nature, the synthesis process of typical generative adversarial networks depends on absolute pixel coordinates in an unhealthy manner. This manifests itself as, e.g., detail appearing to be glued to image coordinates instead of the surfaces of depicted objects. We trace the root cause to careless signal processing that causes aliasing in the generator network. Interpreting all signals in the network as continuous, we derive generally applicable, small architectural changes that guarantee that unwanted information cannot leak into the hierarchical synthesis process. The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales. Our results pave the way for generative models better suited for video and animation.
@incollection{Karras2021neurips,
author = {Tero Karras and Miika Aittala and Samuli Laine and Erik H\"ark\"onen and Janne Hellsten and Jaakko Lehtinen and Timo Aila},
title = {Alias-Free Generative Adversarial Networks},
booktitle = {Advances in Neural Information Processing Systems 34 (proc. NeurIPS 2021)},
year = {2021}
}
AbstractWe present a modular differentiable renderer design that yields performance superior to previous methods by leveraging existing, highly optimized hardware graphics pipelines. Our design supports all crucial operations in a modern graphics pipeline: rasterizing large numbers of triangles, attribute interpolation, filtered texture lookups, as well as user-programmable shading and geometry processing, all in high resolutions. Our modular primitives allow custom, high-performance graphics pipelines to be built directly within automatic differentiation frameworks such as PyTorch or TensorFlow. As a motivating application, we formulate facial performance capture as an inverse rendering problem and show that it can be solved efficiently using our tools. Our results indicate that this simple and straightforward approach achieves excellent geometric correspondence between rendered results and reference imagery.
@article{Laine2020sa,
author = {Samuli Laine and Janne Hellsten and Tero Karras and Yeongho Seol and Jaakko Lehtinen and Timo Aila},
title = {Modular Primitives for High-Performance Differentiable Rendering},
journal = {ACM Transactions on Graphics (Proc. SIGGRAPH Asia)},
volume = 39,
number = 6,
year = {2020},
pages = {Article No.: 194}
}
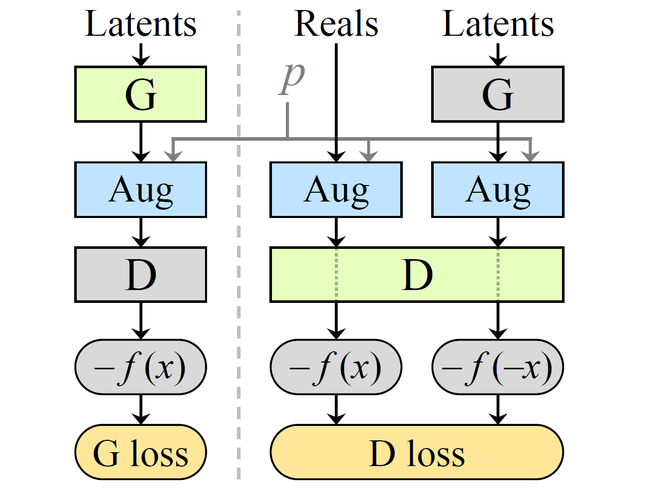
AbstractTraining generative adversarial networks (GAN) using too little data typically leads to discriminator overfitting, causing training to diverge. We propose an adaptive discriminator augmentation mechanism that significantly stabilizes training in limited data regimes. The approach does not require changes to loss functions or network architectures, and is applicable both when training from scratch and when fine-tuning an existing GAN on another dataset. We demonstrate, on several datasets, that good results are now possible using only a few thousand training images, often matching StyleGAN2 results with an order of magnitude fewer images. We expect this to open up new application domains for GANs. We also find that the widely used CIFAR-10 is, in fact, a limited data benchmark, and improve the record FID from 5.59 to 2.42.
@inproceedings{Karras2020neurips,
author = {Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila},
title = { Training Generative Adversarial Networks with Limited Data},
booktitle = {Proc. Neural Information Processing Systems (NeurIPS)},
year = {2020},
}
AbstractThe style-based GAN architecture (StyleGAN) yields state-of-the-art results in data-driven unconditional generative image modeling. We expose and analyze several of its characteristic artifacts, and propose changes in both model architecture and training methods to address them. In particular, we redesign the generator normalization, revisit progressive growing, and regularize the generator to encourage good conditioning in the mapping from latent codes to images. In addition to improving image quality, this path length regularizer yields the additional benefit that the generator becomes significantly easier to invert. This makes it possible to reliably attribute a generated image to a particular network. We furthermore visualize how well the generator utilizes its output resolution, and identify a capacity problem, motivating us to train larger models for additional quality improvements. Overall, our improved model redefines the state of the art in unconditional image modeling, both in terms of existing distribution quality metrics as well as perceived image quality.
@inproceedings{Karras2020cvpr,
author = {Tero Karras and Samuli Laine and Miika Aittala and Janne Hellsten and Jaakko Lehtinen and Timo Aila},
title = {Analyzing and Improving the Image Quality of {StyleGAN}},
booktitle = {Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2020},
}
AbstractConsistency regularization describes a class of approaches that have yielded ground breaking results in semi-supervised classification problems. Prior work has established the cluster assumption - under which the data distribution consists of uniform class clusters of samples separated by low density regions - as important to its success. We analyze the problem of semantic segmentation and find that its' distribution does not exhibit low density regions separating classes and offer this as an explanation for why semi-supervised segmentation is a challenging problem, with only a few reports of success. We then identify choice of augmentation as key to obtaining reliable performance without such low-density regions. We find that adapted variants of the recently proposed CutOut and CutMix augmentation techniques yield state-of-the-art semi-supervised semantic segmentation results in standard datasets. Furthermore, given its challenging nature we propose that semantic segmentation acts as an effective acid test for evaluating semi-supervised regularizers.
@inproceedings{French2020,
author = {Geoff French and Timo Aila and Samuli Laine and Michal Mackiewicz and Graham Finlayson},
title = {Semi-Supervised Semantic Segmentation Needs Strong, High-Dimensional Perturbations},
booktitle = {Proc. British Machine Vision Conference (BMVC)},
year = {2020},
}
AbstractThe ability to automatically estimate the quality and coverage of the samples produced by a generative model is a vital requirement for driving algorithm research. We present an evaluation metric that can separately and reliably measure both of these aspects in image generation tasks by forming explicit, non-parametric representations of the manifolds of real and generated data. We demonstrate the effectiveness of our metric in StyleGAN and BigGAN by providing several illustrative examples where existing metrics yield uninformative or contradictory results. Furthermore, we analyze multiple design variants of StyleGAN to better understand the relationships between the model architecture, training methods, and the properties of the resulting sample distribution. In the process, we identify new variants that improve the state-of-the-art. We also perform the first principled analysis of truncation methods and identify an improved method. Finally, we extend our metric to estimate the perceptual quality of individual samples, and use this to study latent space interpolations.
@inproceedings{Kynkaanniemi2019NeurIPS,
author = {Tuomas Kynk\"a\"anniemi and Tero Karras and Samuli Laine and Jaakko Lehtinen and Timo Aila},
title = {Improved Precision and Recall Metric for Assessing Generative Models},
booktitle = {Proc. Neural Information Processing Systems (NeurIPS)},
year = {2019},
}
AbstractWe describe a novel method for training high-quality image denoising models based on unorganized collections of corrupted images. The training does not need access to clean reference images, or explicit pairs of corrupted images, and can thus be applied in situations where such data is unacceptably expensive or impossible to acquire. We build on a recent technique that removes the need for reference data by employing networks with a "blind spot" in the receptive field, and significantly improve two key aspects: image quality and training efficiency. Our result quality is on par with state-of-the-art neural network denoisers in the case of i.i.d. additive Gaussian noise, and not far behind with Poisson and impulse noise. We also successfully handle cases where parameters of the noise model are variable and/or unknown in both training and evaluation data.
@inproceedings{Laine2019NeurIPS,
author = {Samuli Laine and Tero Karras and Jaakko Lehtinen and Timo Aila},
title = {High-Quality Self-Supervised Deep Image Denoising},
booktitle = {Proc. Neural Information Processing Systems (NeurIPS)},
year = {2019},
}
AbstractUnsupervised image-to-image translation methods learn to map images in a given class to an analogous image in a different class, drawing on unstructured (non-registered) datasets of images. While remarkably successful, current methods require access to many images in both source and destination classes at training time. We argue this greatly limits their use. Drawing inspiration from the human capability of picking up the essence of a novel object from a small number of examples and generalizing from there, we seek a few-shot, unsupervised image-to-image translation algorithm that works on previously unseen target classes that are specified, at test time, only by a few example images. Our model achieves this few-shot generation capability by coupling an adversarial training scheme with a novel network design. Through extensive experimental validation and comparisons to several baseline methods on benchmark datasets, we verify the effectiveness of the proposed framework.
@inproceedings{Liu2019FUNIT,
author = {Ming-Yu Liu and Xun Huang and Arun Mallya and Tero Karras and Timo Aila and Jaakko Lehtinen and Jan Kautz},
title = {Few-shot Unsupervised Image-to-Image Translation},
booktitle = {Proc. International Conference on Computer Vision (ICCV)},
year = {2019},
}
AbstractWe propose an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature. The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identity when trained on human faces) and stochastic variation in the generated images (e.g., freckles, hair), and it enables intuitive, scale-specific control of the synthesis. The new generator improves the state-of-the-art in terms of traditional distribution quality metrics, leads to demonstrably better interpolation properties, and also better disentangles the latent factors of variation. To quantify interpolation quality and disentanglement, we propose two new, automated methods that are applicable to any generator architecture. Finally, we introduce a new, highly varied and high-quality dataset of human faces.
@inproceedings{Karras2019cvpr,
author = {Tero Karras and Samuli Laine and Timo Aila},
title = {A Style-Based Generator Architecture for Generative Adversarial Networks},
booktitle = {Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019},
}
AbstractWe describe a new training methodology for generative adversarial networks. The key idea is to grow both the generator and discriminator progressively: starting from a low resolution, we add new layers that model increasingly fine details as training progresses. This both speeds the training up and greatly stabilizes it, allowing us to produce images of unprecedented quality, e.g., CelebA images at 10242. We also propose a simple way to increase the variation in generated images, and achieve a record inception score of 8.80 in unsupervised CIFAR10. Additionally, we describe several implementation details that are important for discouraging unhealthy competition between the generator and discriminator. Finally, we suggest a new metric for evaluating GAN results, both in terms of image quality and variation. As an additional contribution, we construct a higher-quality version of the CelebA dataset.
@inproceedings{Karras2018iclr,
author = {Tero Karras and Timo Aila and Samuli Laine and Jaakko Lehtinen},
title = {Progressive Growing of {GAN}s for Improved Quality, Stability, and Variation},
booktitle = {Proc. International Conference on Learning Representations (ICLR)},
year = {2018},
}
AbstractWe apply basic statistical reasoning to signal reconstruction by machine learning — learning to map corrupted observations to clean signals — with a simple and powerful conclusion: it is possible to learn to restore images by only looking at corrupted examples, at performance at and sometimes exceeding training using clean data, without explicit image priors or likelihood models of the corruption. In practice, we show that a single model learns photographic noise removal, denoising synthetic Monte Carlo images, and reconstruction of undersampled MRI scans — all corrupted by different processes — based on noisy data only.
@inproceedings{Lehtinen2018,
author = {Jaakko Lehtinen and Jacob Munkberg and Jon Hasselgren and Samuli Laine and Tero Karras and
Miika Aittala and Timo Aila},
title = {{Noise2Noise: L}earning Image Restoration without Clean Data},
booktitle = {Proc. International Conference on Machine Learning (ICML)},
year = {2018},
}
AbstractWe describe a machine learning technique for reconstructing image sequences rendered using Monte Carlo methods. Our primary focus is on reconstruction of global illumination with extremely low sampling budgets at interactive rates. Motivated by recent advances in image restoration with deep convolutional networks, we propose a variant of these networks better suited to the class of noise present in Monte Carlo rendering. We allow for much larger pixel neighborhoods to be taken into account, while also improving execution speed by an order of magnitude. Our primary contribution is the addition of recurrent connections to the network in order to drastically improve temporal stability for sequences of sparsely sampled input images. Our method also has the desirable property of automatically modeling relationships based on auxiliary per-pixel input channels, such as depth and normals. We show significantly higher quality results compared to existing methods that run at comparable speeds, and furthermore argue a clear path for making our method run at realtime rates in the near future.
@article{Chaitanya2017,
author = {Chakravarty Reddy Alla Chaitanya and Anton Kaplanyan and Christoph Schied and Marco Salvi and
Aaron Lefohn and Derek Nowrouzezahrai and Timo Aila},
title = {Interactive Reconstruction of Noisy Monte Carlo Image Sequences using a Recurrent Autoencoder},
journal = {ACM Trans. Graph.},
year = {2017},
volume = {36},
number = {4},
}
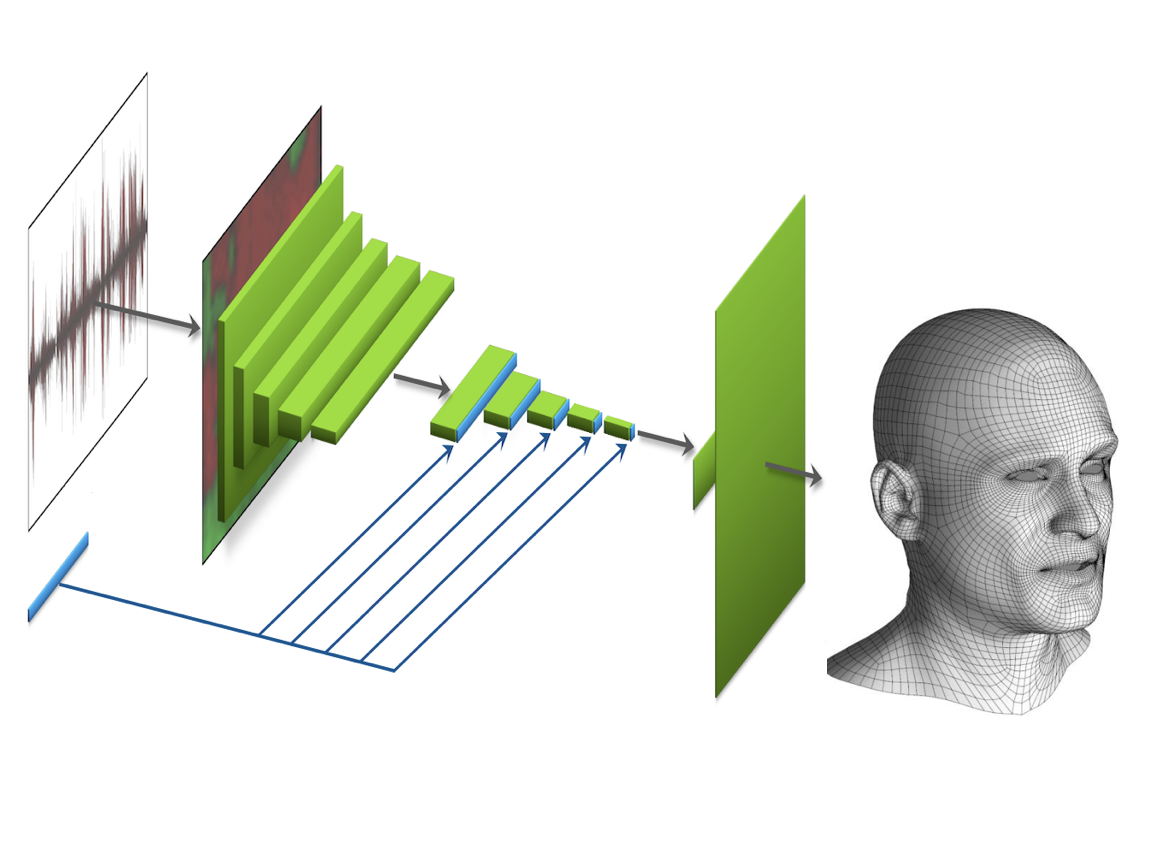
AbstractWe present a machine learning technique for driving 3D facial animation by audio input in real time and with low latency. Our deep neural network learns a mapping from input waveforms to the 3D vertex coordinates of a face model, and simultaneously discovers a compact, latent code that disambiguates the variations in facial expression that cannot be explained by the audio alone. During inference, the latent code can be used as an intuitive control for the emotional state of the face puppet. We train our network with 3-5 minutes of high-quality animation data obtained using traditional, vision-based performance capture methods. Even though our primary goal is to model the speaking style of a single actor, our model yields reasonable results even when driven with audio from other speakers with different gender, accent, or language, as we demonstrate with a user study. The results are applicable to in-game dialogue, low-cost localization, virtual reality avatars, and telepresence.
@article{Karras2017,
author = {Tero Karras and Timo Aila and Samuli Laine and Antti Herva and Jaakko Lehtinen},
title = {Audio-Driven Facial Animation by Joint End-to-End Learning of Pose and Emotion},
journal = {ACM Trans. Graph.},
year = {2017},
volume = {36},
number = {4},
}
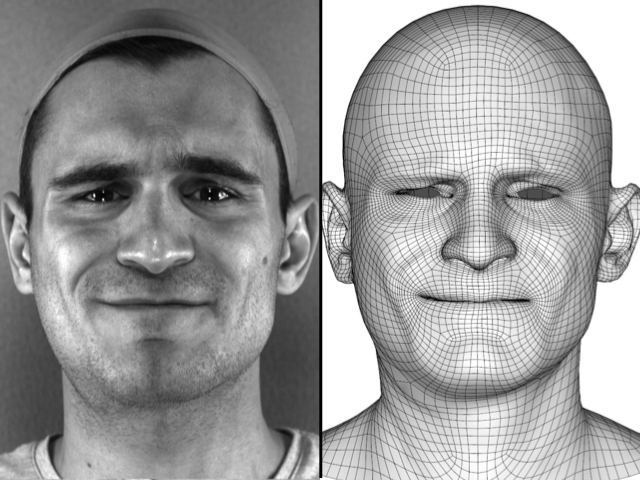
AbstractWe present a real-time deep learning framework for video-based facial performance capture -- the dense 3D tracking of an actor's face given a monocular video. Our pipeline begins with accurately capturing a subject using a high-end production facial capture pipeline based on multi-view stereo tracking and artist-enhanced animations. With 5--10 minutes of captured footage, we train a convolutional neural network to produce high-quality output, including unseen and occluded regions, from a monocular video sequence of that subject. Since this 3D facial performance capture is fully automated, our system can drastically reduce the amount of labor involved in the development of modern narrative-driven video games or films involving realistic digital doubles of actors and potentially hours of animated dialogue per character. We compare our results with several state-of-the-art monocular real-time facial capture techniques and demonstrate compelling animation inference in challenging areas such as eyes and lips.
@inproceedings{Laine2017,
author = {Samuli Laine, Tero Karras, Timo Aila, Antti Herva, Shunsuke Saito, Ronald Yu, Hao Li, and Jaakko Lehtinen},
title = {Production-Level Facial Performance Capture Using Deep Convolutional Neural Networks},
journal = {Proc. Symposium on Computer Animation (SCA)},
year = {2017},
}
 |
Temporal Ensembling for Semi-Supervised Learning. Samuli Laine and Timo Aila. International Conference on Learning Representations (ICLR) 2017. Abstract Bibtex PDF Implementation |
In this paper, we present a simple and efficient method for training deep neural networks in a semi-supervised setting where only a small portion of training data is labeled. We introduce self-ensembling, where we form a consensus prediction of the unknown labels using the outputs of the network-in-training on different epochs, and most importantly, under different regularization and input augmentation conditions. This ensemble prediction can be expected to be a better predictor for the unknown labels than the output of the network at the most recent training epoch, and can thus be used as a target for training. Using our method, we set new records for two standard semi-supervised learning benchmarks, reducing the (non-augmented) classification error rate from 18.44% to 7.05% in SVHN with 500 labels and from 18.63% to 16.55% in CIFAR-10 with 4000 labels, and further to 5.12% and 12.16% by enabling the standard augmentations. We additionally obtain a clear improvement in CIFAR-100 classification accuracy by using random images from the Tiny Images dataset as unlabeled extra inputs during training. Finally, we demonstrate good tolerance to incorrect labels.
@inproceedings{Laine2017,
author = {Samuli Laine and Timo Aila},
title = {Temporal Ensembling for Semi-Supervised Learning},
journal = {Proc. International Conference on Learning Representations (ICLR)},
year = {2017},
}
AbstractWe propose a new formulation for pruning convolutional kernels in neural networks to enable efficient inference. We interleave greedy criteria-based pruning with fine-tuning by backpropagation�a computationally efficient procedure that maintains good generalization in the pruned network. We propose a new criterion based on Taylor expansion that approximates the change in the cost function induced by pruning network parameters. We focus on transfer learning, where large pretrained networks are adapted to specialized tasks. The proposed criterion demonstrates superior performance compared to other criteria, e.g. the norm of kernel weights or feature map activation, for pruning large CNNs after adaptation to fine-grained classification tasks (Birds-200 and Flowers-102) relaying only on the first order gradient information. We also show that pruning can lead to more than 10x theoretical reduction in adapted 3D-convolutional filters with a small drop in accuracy in a recurrent gesture classifier. Finally, we show results for the large-scale ImageNet dataset to emphasize the flexibility of our approach.
@inproceedings{Laine2017,
author = {Pavlo Molchanov and Stephen Tyree and Tero Karras and Timo Aila and Jan Kautz},
title = {Pruning Convolutional Neural Networks for Resource Efficient Inference},
journal = {Proc. International Conference on Learning Representations (ICLR)},
year = {2017},
}
AbstractBinary gradient cameras extract edge and temporal information directly on the sensor, allowing for low-power, low-bandwidth, and high-dynamic-range capabilities -- all critical factors for the deployment of embedded computer vision systems. However, these types of images require specialized computer vision algorithms and are not easy to interpret by a human observer. In this paper we propose to recover an intensity image from a single binary spatial gradient image with a deep autoencoder. Extensive experimental results on both simulated and real data show the effectiveness of the proposed approach.
@inproceedings{Jayasuriya2017,
author = {Suren Jayasuriya and Orazio Gallo and Jinwei Gu and Timo Aila and Jan Kautz},
title = {Reconstructing Intensity Images from Binary Spatial Gradient Cameras},
journal = {IEEE Workshop on Embedded Vision (CVPR)},
year = {2017},
}
 |
Reflectance Modeling by Neural Texture Synthesis. Miika Aittala, Timo Aila, and Jaakko Lehtinen. ACM Transactions on Graphics 35(4) (SIGGRAPH 2016). Abstract Bibtex Project page |
We extend parametric texture synthesis to capture rich, spatially varying parametric reflectance models from a single image. Our input is a single head-lit flash image of a mostly flat, mostly stationary (textured) surface, and the output is a tile of SVBRDF parameters that reproduce the appearance of the material. No user intervention is required. Our key insight is to make use of a recent, powerful texture descriptor based on deep convolutional neural network statistics for ``softly'' comparing the model prediction and the examplars without requiring an explicit point-to-point correspondence between them. This is in contrast to traditional reflectance capture that requires pointwise constraints between inputs and outputs under varying viewing and lighting conditions. Seen through this lens, our method is an indirect algorithm for fitting photorealistic SVBRDFs. The problem is severely ill-posed and non-convex. To guide the optimizer towards desirable solutions, we introduce a soft Fourier-domain prior for encouraging spatial stationarity of the reflectance parameters and their correlations, and a complementary preconditioning technique that enables efficient exploration of such solutions by L-BFGS, a standard non-linear numerical optimizer.
@article{Aittala2016sg,
author = {Miika Aittala and Timo Aila and Jaakko Lehtinen},
title = {Reflectance Modeling by Neural Texture Synthesis},
journal = {ACM Trans. Graph.},
year = {2016},
volume = {35},
number = {4},
}
AbstractWe introduce a novel Metropolis rendering algorithm that directly computes image gradients, and reconstructs the final image from the gradients by solving a Poisson equation. The reconstruction is aided by a low-fidelity approximation of the image computed during gradient sampling. As an extension of path-space Metropolis light transport, our algorithm is well suited for difficult transport scenarios. We demonstrate that our method outperforms the state-of-the-art in several well-known test scenes. Additionally, we analyze the spectral properties of gradient-domain sampling, and compare it to the traditional image-domain sampling.
@article{Lehtinen2013sg,
author = {Jaakko Lehtinen and Tero Karras and Samuli Laine and Miika Aittala and Fr\'{e}do Durand and Timo Aila},
title = {Gradient-Domain {Metropolis} Light Transport},
journal = {ACM Trans. Graph.},
year = {2013},
volume = {32},
number = {4},
}
 |
On Quality Metrics of Bounding Volume Hierarchies. Timo Aila, Tero Karras, and Samuli Laine. High-Performance Graphics 2013. Best paper award. Abstract Bibtex PDF Slides (Keynote) Slides (PDF) |
The surface area heuristic (SAH) is widely used as a predictor for ray tracing performance, and as a heuristic to guide the construction of spatial acceleration structures. We investigate how well SAH actually predicts ray tracing performance of a bounding volume hierarchy (BVH), observe that this relationship is far from perfect, and then propose two new metrics that together with SAH almost completely explain the measured performance. Our observations shed light on the increasingly common situation that a supposedly good tree construction algorithm produces trees that are slower to trace than expected. We also note that the trees constructed using greedy top-down algorithms are consistently faster to trace than SAH indicates and are also more SIMD-friendly than competing approaches.
@inproceedings{Aila2013hpg,
author = {Timo Aila and Tero Karras and Samuli Laine},
title = {On Quality Metrics of Bounding Volume Hierarchies},
booktitle = {Proc. High-Performance Graphics},
year = {2013},
}
 |
Megakernels Considered Harmful: Wavefront Path Tracing on GPUs. Samuli Laine, Tero Karras, and Timo Aila. High-Performance Graphics 2013. Best paper 2nd place. Abstract Bibtex PDF |
When programming for GPUs, simply porting a large CPU program into an equally large GPU kernel is generally not a good approach. Due to SIMT execution model on GPUs, divergence in control flow carries substantial performance penalties, as does high register usage that lessens the latency-hiding capability that is essential for the high-latency, high-bandwidth memory system of a GPU. In this paper, we implement a path tracer on a GPU using a wavefront formulation, avoiding these pitfalls that can be especially prominent when using materials that are expensive to evaluate. We compare our performance against the traditional megakernel approach, and demonstrate that the wavefront formulation is much better suited for real-world use cases where multiple complex materials are present in the scene.
@inproceedings{Laine2013hpg,
author = {Samuli Laine and Tero Karras and Timo Aila},
title = {Megakernels Considered Harmful: Wavefront Path Tracing on GPUs},
booktitle = {Proc. High-Performance Graphics},
year = {2013},
}
 |
Fast Parallel Construction of High-Quality Bounding Volume Hierarchies. Tero Karras and Timo Aila. High-Performance Graphics 2013. Best paper 3rd place. Abstract Bibtex PDF Full results |
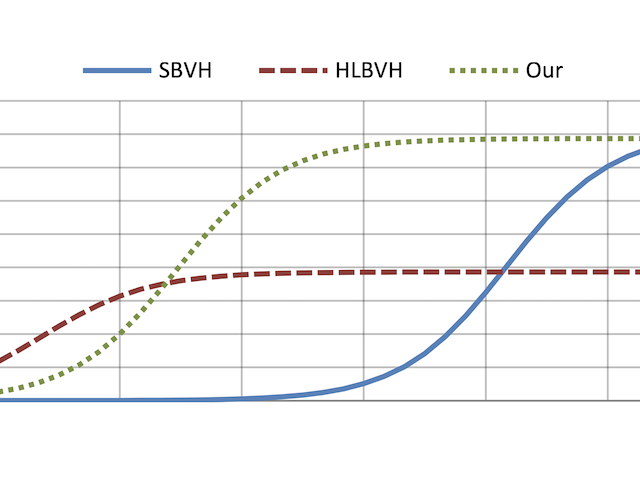
We propose a new massively parallel algorithm for constructing high-quality bounding volume hierarchies (BVHs) for ray tracing. The algorithm is based on modifying an existing BVH to improve its quality, and executes in linear time at a rate of almost 40M triangles/sec on NVIDIA GTX Titan. We also propose an improved approach for parallel splitting of triangles prior to tree construction. Averaged over 20 test scenes, the resulting trees offer over 90% of the ray tracing performance of the best offline construction method (SBVH), while previous fast GPU algorithms offer only about 50%. Compared to state-of-the-art, our method offers a significant improvement in the majority of practical workloads that need to construct the BVH for each frame. On the average, it gives the best overall performance when tracing between 7 million and 60 billion rays per frame. This covers most interactive applications, product and architectural design, and even movie rendering.
@inproceedings{Karras2013hpg,
author = {Tero Karras and Timo Aila},
title = {Fast Parallel Construction of High-Quality Bounding Volume Hierarchies},
booktitle = {Proc. High-Performance Graphics},
year = {2013},
}
AbstractStochastic techniques for rendering indirect illumination suffer from noise due to the variance in the integrand. In this paper, we describe a general reconstruction technique that exploits anisotropy in the light field and permits efficient reuse of input samples between pixels or world-space locations, multiplying the effective sampling rate by a large factor. Our technique introduces visibility-aware anisotropic reconstruction to indirect illumination, ambient occlusion and glossy reflections. It operates on point samples without knowledge of the scene, and can thus be seen as an advanced image filter. Our results show dramatic improvement in image quality while using very sparse input samplings.
@article{Lehtinen2012sg,
author = {Jaakko Lehtinen and Timo Aila and Samuli Laine and Fr\'{e}do Durand},
title = {Reconstructing the Indirect Light Field for Global Illumination},
journal = {ACM Trans. Graph.},
year = {2012},
volume = {31},
number = {4},
}
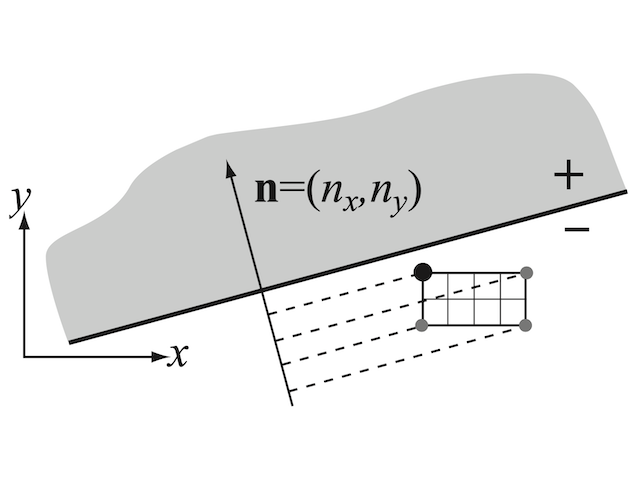
ErrataTowards the end of Section 2.3.2 the text should read "If the intersection point lies within the positive or negative halfspaces of both samples, a conflict is declared, cf. Figure 5."
In Section 3.1 the time to render 8spp with PBRT should be 62.7s instead of 36.6s, and consequently the speedup of our method should be 15.5x instead of 18x.
AbstractWe present a novel method for increasing the efficiency of stochastic rasterization of motion and defocus blur. Contrary to earlier approaches, our method is efficient even with the low sampling densities commonly encountered in realtime rendering, while allowing the use of arbitrary sampling patterns for maximal image quality. Our clipless dual-space formulation avoids problems with triangles that cross the camera plane during the shutter interval. The method is also simple to plug into existing rendering systems.
@article{Laine2011sg,
author = {Samuli Laine and Timo Aila and Tero Karras and Jaakko Lehtinen},
title = {Clipless Dual-Space Bounds for Faster Stochastic Rasterization},
journal = {ACM Trans. Graph.},
year = {2011},
volume = {30},
number = {4},
}
AbstractTraditionally, effects that require evaluating multidimensional integrals for each pixel, such as motion blur, depth of field, and soft shadows, suffer from noise due to the variance of the highdimensional integrand. In this paper, we describe a general reconstruction technique that exploits the anisotropy in the temporal light field and permits efficient reuse of samples between pixels, multiplying the effective sampling rate by a large factor. We show that our technique can be applied in situations that are challenging or impossible for previous anisotropic reconstruction methods, and that it can yield good results with very sparse inputs. We demonstrate our method for simultaneous motion blur, depth of field, and soft shadows.
@article{Lehtinen2011sg,
author = {Jaakko Lehtinen and Timo Aila and Jiawen Chen and Samuli Laine and Fr\'{e}do Durand},
title = {Temporal Light Field Reconstruction for Rendering Distribution Effects},
journal = {ACM Trans. Graph.},
year = {2011},
volume = {30},
number = {4},
}
AbstractStochastic renderers produce unbiased but noisy images of scenes that include the advanced camera effects of motion and defocus blur and possibly other effects such as transparency. We present a simple algorithm that selectively adds bias in the form of image space blur to pixels that are unlikely to have high frequency content in the final image. For each pixel, we sweep once through a fixed neighborhood of samples in front to back order, using a simple accumulation scheme. We achieve good quality images with only 16 samples per pixel, making the algorithm potentially practical for interactive stochastic rendering in the near future.
@InProceedings{Shirley2011i3d,
author = {Peter Shirley and Timo Aila and Jonathan Cohen and Eric Enderton and Samuli Laine and
David Luebke and Morgan Mc{G}uire},
title = {A Local Image Reconstruction Algorithm for Stochastic Rendering},
booktitle = {Proc. Symposium on Interactive 3D Graphics and Games 2011},
pages = {9--13},
year = {2011},
publisher = {ACM Press},
}
 |
Architecture Considerations for Tracing Incoherent Rays. Timo Aila and Tero Karras. High-Performance Graphics 2010. Abstract Bibtex PDF Slides |
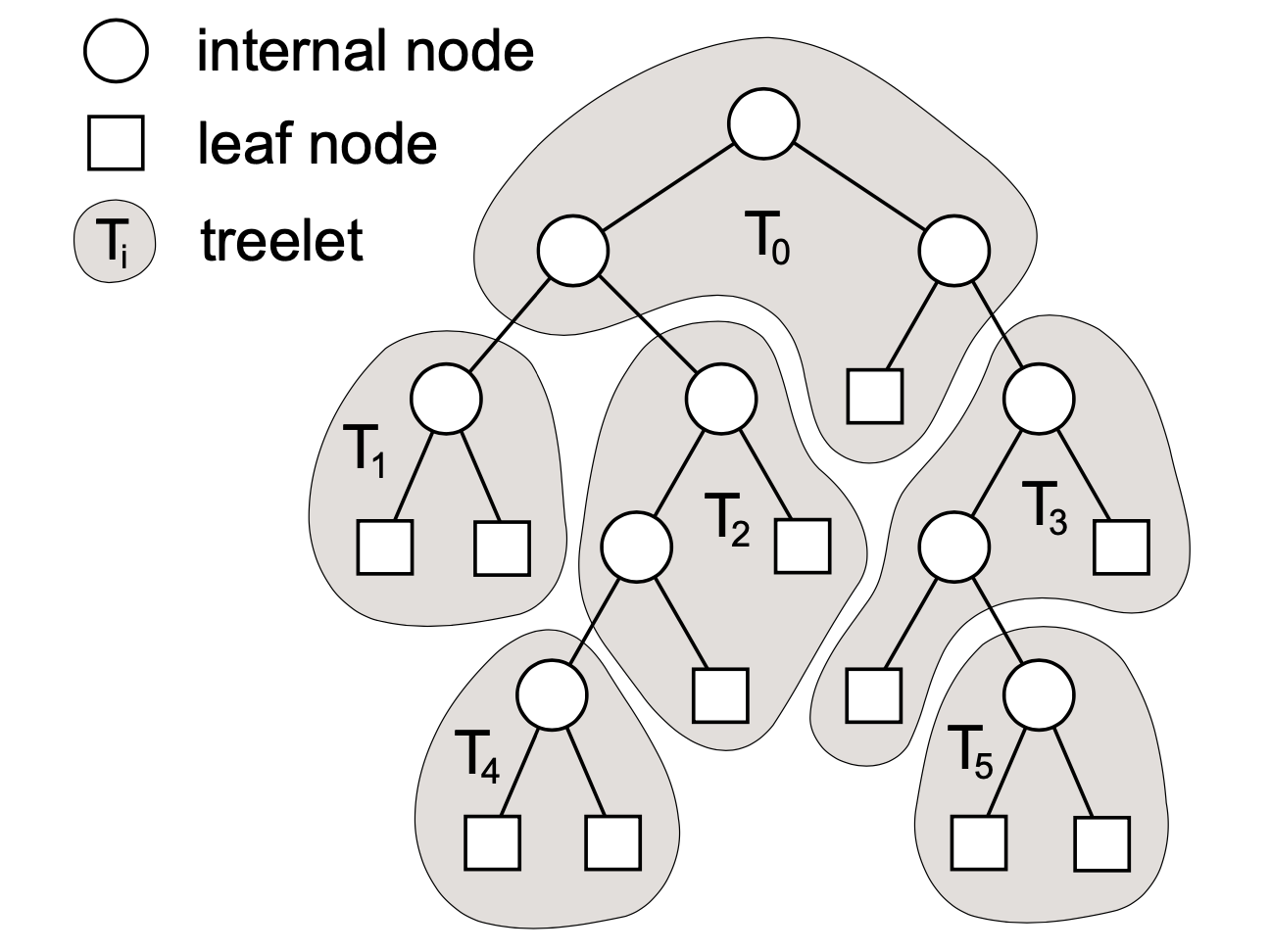
This paper proposes a massively parallel hardware architecture for efficient tracing of incoherent rays, e.g. for global illumination. The general approach is centered around hierarchical treelet subdivision of the acceleration structure and repeated queueing/postponing of rays to reduce cache pressure. We describe a heuristic algorithm for determining the treelet subdivision, and show that our architecture can reduce the total memory bandwidth requirements by up to 90% in difficult scenes. Furthermore the architecture allows submitting rays in an arbitrary order with practically no performance penalty. We also conclude that scheduling algorithms can have an important effect on results, and that using fixed-size queues is not an appealing design choice. Increased auxiliary traffic, including traversal stacks, is identified as the foremost remaining challenge of this architecture.
@InProceedings{Aila2010hpg,
author = {Timo Aila and Tero Karras},
title = {Architecture Considerations for Tracing Incoherent Rays},
booktitle = {Proc. High-Performance Graphics 2010},
pages = {113--122},
year = {2010},
}
AbstractWe describe the architecture of a novel system for precomputing sparse directional occlusion caches. These caches are used for accelerating a fast cinematic lighting pipeline that works in the spherical harmonics domain. The system was used as a primary lighting technology in the movie Avatar, and is able to efficiently handle massive scenes of unprecedented complexity through the use of a flexible, stream-based geometry processing architecture, a novel out-of-core algorithm for creating efficient ray tracing acceleration structures, and a novel out-of-core GPU ray tracing algorithm for the computation of directional occlusion and spherical integrals at arbitrary points.
@article{Pantaleoni2010Siggraph,
author = {Jacopo Pantaleoni and Luca Fascione and Martin Hall and Timo Aila},
title = {PantaRay: Fast Ray-traced Occlusion Caching of Massive Scenes},
journal = {ACM Trans. Graph.},
volume = {29},
number = {4},
pages = {37:1--37:10},
year = {2010},
}
AbstractWe discuss the mapping of elementary ray tracing operations---acceleration structure traversal and primitive intersection---onto wide SIMD/SIMT machines. Our focus is on NVIDIA GPUs, but some of the observations should be valid for other wide machines as well. While several fast GPU tracing methods have been published, very little is actually understood about their performance. Nobody knows whether the methods are anywhere near the theoretically obtainable limits, and if not, what might be causing the discrepancy. We study this question by comparing the measurements against a simulator that tells the upper bound of performance for a given kernel. We observe that previously known methods are a factor of 1.5--2.5X off from theoretical optimum, and most of the gap is not explained by memory bandwidth, but rather by previously unidentified inefficiencies in hardware work distribution. We then propose a simple solution that significantly narrows the gap between simulation and measurement. This results in the fastest GPU ray tracer to date. We provide results for primary, ambient occlusion and diffuse interreflection rays.
@InProceedings{Aila2009hpg,
author = {Timo Aila and Samuli Laine},
title = {Understanding the Efficiency of Ray Traversal on GPUs},
booktitle = {Proc. High-Performance Graphics 2009},
pages = {145--149},
year = {2009},
}
AbstractWe introduce a meshless hierarchical representation for solving light transport problems. Precomputed radiance transfer (PRT) and ?nite elements require a discrete representation of illumination over the scene. Non-hierarchical approaches such as per-vertex values are simple to implement, but lead to long precomputation. Hier- archical bases like wavelets lead to dramatic acceleration, but in their basic form they work well only on �at or smooth surfaces. We introduce a hierarchical function basis induced by scattered data approximation. It is decoupled from the geometric representation, allowing the hierarchical representation of illumination on complex objects. We present simple data structures and algorithms for con- structing and evaluating the basis functions. Due to its hierarchical nature, our representation adapts to the complexity of the illumi- nation, and can be queried at different scales. We demonstrate the power of the new basis in a novel precomputed direct-to-indirect light transport algorithm that greatly increases the complexity of scenes that can be handled by PRT approaches.
@article{Lehtinen2008Hierarchical,
author = {Jaakko Lehtinen and Matthias Zwicker and Emmanuel Turquin and Janne Kontkanen and Fr\'{e}do Durand and Fran\c{c}ois Sillion and Timo Aila},
title = {A Meshless Hierarchical Representation for Light Transport},
journal = {ACM Trans. Graph.},
volume = 27,
number = 3,
pages = {Article 37},
year = {2008},
}
AbstractWe present a method for rendering single-bounce indirect illumination in real time on currently available graphics hardware. The method is based on the instant radiosity algorithm, where virtual point lights (VPLs) are generated by casting rays from the primary light source. Hardware shadow maps are then employed for determining the indirect illumination from the VPLs. Our main contribution is an algorithm for reusing the VPLs and incrementally maintaining their good distribution. As a result, only a few shadow maps need to be rendered per frame as long as the motion of the primary light source is reasonably smooth. This yields real-time frame rates even when hundreds of VPLs are used.
@InProceedings{Laine2007egsr,
author = {Samuli Laine and Hannu Saransaari and Janne Kontkanen and Jaakko Lehtinen and Timo Aila},
title = {Incremental Instant Radiosity for Real-Time Indirect Illumination},
booktitle = {Proc. Eurographics Symposium on Rendering 2007},
pages = {277--286},
year = {2007},
publisher = {Eurographics Association},
}
AbstractWe present a novel architecture for hardware-accelerated rendering of point primitives. Our pipeline implements a refined version of EWA splatting, a high quality method for antialiased rendering of point sampled representations. A central feature of our design is the seamless integration of the architecture into conventional, OpenGL-like graphics pipelines so as to complement triangle-based rendering. The specific properties of the EWA algorithm required a variety of novel design concepts including a ternary depth test and using an on-chip pipelined heap data structure for making the memory accesses of splat primitives more coherent. In addition, we developed a computationally stable evaluation scheme for perspectively corrected splats. We implemented our architecture both on reconfigurable FPGA boards and as an ASIC prototype, and we integrated it into an OpenGL-like software implementation. Our evaluation comprises a detailed performance analysis using scenes of varying complexity.
@article{Weyrich2007siggraph,
author = {Tim Weyrich and Simon Heinzle and Timo Aila and Daniel Fasnacht and Stephan Oetiker and Mario Botsch and
Cyril Flaig and Simon Mall and Kaspar Rohrer and Norbert Felber and Hubert Kaeslin and Markus Gross},
title = {A Hardware Architecture for Surface Splatting},
journal = {ACM Trans. Graph.},
volume = {26},
number = {3},
year = {2007},
pages = {Article 90},
}
 |
Ambient Occlusion for Animated Characters. Janne Kontkanen and Timo Aila. Eurographics Symposium on Rendering 2006. Abstract Bibtex PDF |
We present a novel technique for approximating ambient occlusion of animated objects. Our method automatically determines the correspondence between animation parameters and per-vertex ambient occlusion using a set of reference poses as its input. Then, at runtime, the ambient occlusion is approximated by taking a dot product between the current animation parameters and static per-vertex coefficients. According to our results, both the computational and storage requirements are low enough for the technique to be directly applicable to computer games running on current graphics hardware. The resulting images are also significantly more realistic than the commonly used static ambient occlusion solutions.
@InProceedings{Kontkanen2006egsr,
author = {Janne Kontkanen and Timo Aila},
title = {Ambient Occlusion for Animated Characters},
booktitle = {Proc. Eurographics Symposium on Rendering 2006},
pages = {343--348},
year = {2006},
publisher = {Eurographics Association},
}
 |
A Weighted Error Metric and Optimization Method for Antialiasing patterns. Samuli Laine and Timo Aila. Computer Graphics Forum 25(1), 2006. Abstract Bibtex PDF Pattern page |
Displaying a synthetic image on a computer display requires determining the colors of individual pixels. To avoid aliasing, multiple samples of the image can be taken per pixel, after which the color of a pixel may be computed as a weighted sum of the samples. The positions and weights of the samples play a major role in the resulting image quality, especially in real-time applications where usually only a handful of samples can be afforded per pixel. This paper presents a new error metric and an optimization method for antialiasing patterns used in image reconstruction. The metric is based on comparing the pattern against a given reference reconstruction filter in spatial domain and it takes into account psychovisually measured angle-specific acuities for sharp features.
@article{Laine2006cgf,
author = {Samuli Laine and Timo Aila},
title = {A Weighted Error Metric and Optimization Method for Antialiasing Patterns},
journal = {Computer Graphics Forum},
volume = {25},
number = {1},
year = {2006},
pages = {83--94},
publisher = {Eurographics Association and Blackwell Publishing Ltd},
}
 |
An Improved Physically-Based Soft Shadow Volume Algorithm. Jaakko Lehtinen, Samuli Laine, and Timo Aila. Computer Graphics Forum 25(3) (Eurographics 2006). Abstract Bibtex PDF |
We identify and analyze several performance problems in a state-of-the-art physically-based soft shadow volume algorithm, and present an improved method that alleviates these problems by replacing an overly conservative spatial acceleration structure by a more efficient one. The new technique consistently outperforms both the previous method and a ray tracing-based reference solution in several realistic situations while retaining the correctness of the solution and other desirable characteristics of the previous method. These include the unintrusiveness of the original algorithm, meaning that our method can be used as a black-box shadow solver in any offline renderer without requiring multiple passes over the image or other special accommodation. We achieve speedup factors from 1.6 to 12.3 when compared to the previous method.
@article{Lehtinen2006eurographics,
author = {Jaakko Lehtinen and Samuli Laine and Timo Aila},
title = {An Improved Physically-Based Soft Shadow Volume Algorithm},
journal = {Computer Graphics Forum},
volume = {25},
number = {3},
year = {2006},
publisher = {Eurographics Association and Blackwell Publishing Ltd},
}
AbstractWe present a new, fast algorithm for rendering physically-based soft shadows in ray tracing-based renderers. Our method replaces the hundreds of shadow rays commonly used in stochastic ray tracers with a single shadow ray and a local reconstruction of the visibility function. Compared to tracing the shadow rays, our algorithm produces exactly the same image while executing one to two orders of magnitude faster in the test scenes used. Our first contribution is a two-stage method for quickly determining the silhouette edges that overlap an area light source, as seen from the point to be shaded. Secondly, we show that these partial silhouettes of occluders, along with a single shadow ray, are sufficient for reconstructing the visibility function between the point and the light source.
@article{laine2005siggraph,
author = {Samuli Laine and Timo Aila and Ulf Assarsson and Jaakko Lehtinen and Tomas Akenine-M\&\#246;ller},
title = {Soft Shadow Volumes for Ray Tracing},
journal = {ACM Trans. Graph.},
volume = {24},
number = {3},
year = {2005},
pages = {1156--1165},
publisher = {ACM Press},
}
 |
Hierarchical Penumbra Casting. Samuli Laine and Timo Aila. Computer Graphics Forum 24(3) (Eurographics 2005). Abstract Bibtex PDF Slides |
We present a novel algorithm for rendering physically-based soft shadows in complex scenes. Instead of casting shadow rays, we place both the points to be shaded and the samples of an area light source into separate hierarchies, and compute hierarchically the shadows caused by each occluding triangle. This yields an efficient algorithm with memory requirements independent of the complexity of the scene.
@article{Laine2005eurographics,
author = {Samuli Laine and Timo Aila},
title = {Hierarchical Penumbra Casting},
journal = {Computer Graphics Forum},
volume = {24},
number = {3},
year = {2005},
pages = {313--322},
publisher = {Eurographics Association and Blackwell Publishing Ltd},
}
 |
Conservative and Tiled Rasterization Using a Modified Triangle Setup. Tomas Akenine-Möller and Timo Aila. Journal of Graphics Tools 10(3), 2005. Abstract Bibtex PDF (draft) JGT Page |
Several algorithms that use graphics hardware to accelerate processing require conservative rasterization in order to function correctly. Conservative rasterization stands for either overestimating or underestimating the size of the triangles. Overestimation is carried out by including all pixels that are at least partially overlapped by the triangle, whereas underestimation includes only the pixels that are fully inside the triangle. None or few algorithms for conservative rasterization have been described in the literature, and current hardware does not explicitly support it. Therefore, we present a simple algorithm, which requires only a small modification to the triangle setup when edge functions are used. Furthermore, the same algorithm can be used for tiled rasterization, where all pixels in a tile (e.g. 8x8 pixels) are visited before moving to the next tile.
@article{AkenineMoller2005jgt,
author = {Tomas Akenine-M\&\#246;ller and Timo Aila},
title = {Conservative and Tiled Rasterization Using a Modified Triangle Setup},
journal = {Journal of Graphics Tools},
volume = {10},
number = {3},
year = {2005},
pages = {1--8},
publisher = {AK Peters Ltd},
}
 |
A Hierarchical Shadow Volume Algorithm. Timo Aila and Tomas Akenine-Möller. Graphics Hardware 2004. Abstract Bibtex PDF Slides |
The shadow volume algorithm is a popular technique for real-time shadow generation using graphics hardware. Its major disadvantage is that it is inherently fillrate-limited, as the performance is inversely proportional to the area of the projected shadow volumes. We present a new algorithm that reduces the shadow volume rasterization work significantly. With our algorithm, the amount of per-pixel processing becomes proportional to the screenspace length of the visible shadow boundary instead of the projected area. The first stage of the algorithm finds 8x8 pixel tiles, whose 3D bounding boxes are either completely inside or outside the shadow volume.
After that, the second stage performs per-pixel computations only for the potential shadow boundary tiles. We outline a two-pass implementation, and also describe an efficient single-pass hardware architecture, in which the two stages are separated using a delay stream. The only modification required in applications is a new pair of calls for marking the beginning and end of a shadow volume. In our test scenes, the algorithm processes up to 11.5 times fewer pixels compared to current state-of-the-art methods, while reducing the external video memory bandwidth by a factor of up to 17.1.
@InProceedings{Aila2004gh,
author = {Timo Aila and Tomas Akenine-M\"oller},
title = {A Hierarchical Shadow Volume Algorithm},
booktitle = {Proc. Graphics Hardware 2004},
pages = {15--23},
year = {2004},
publisher = {Eurographics Association}
}
 |
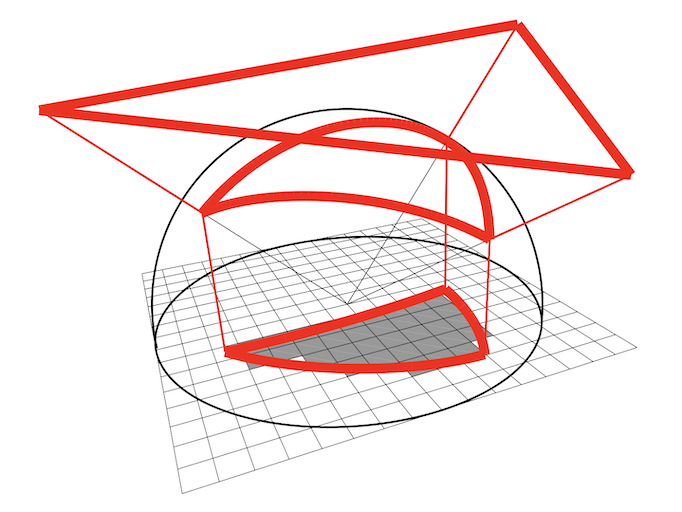
Alias-Free Shadow Maps. Timo Aila and Samuli Laine. Eurographics Symposium on Rendering 2004. Abstract Bibtex PDF Slides |
In this paper we abandon the regular structure of shadow maps. Instead, we transform the visible pixels P(x,y,z) from screen space to the image plane of a light source P'(x',y',z'). The (x',y') are then used as sampling points when the geometry is rasterized into the shadow map. This eliminates the resolution issues that have plagued shadow maps for decades, e.g., jagged shadow boundaries. Incorrect self-shadowing is also greatly reduced, and semi-transparent shadow casters and receivers can be supported. A hierarchical software implementation is outlined.
@InProceedings{Aila2004egsr,
author = {Timo Aila and Samuli Laine},
title = {Alias-Free Shadow Maps},
booktitle = {Proc. Eurographics Symposium on Rendering 2004},
pages = {161--166},
year = {2004},
publisher = {Eurographics Association},
}
 |
Hemispherical Rasterization for Self-Shadowing of Dynamic Objects. Jan Kautz, Jaakko Lehtinen, and Timo Aila. Eurographics Symposium on Rendering 2004. Abstract Bibtex PDF |
We present a method for interactive rendering of dynamic models with self-shadows due to time-varying, low-frequency lighting environments. In contrast to previous techniques, the method is not limited to static or pre-animated models. Our main contribution is a hemispherical rasterizer, which rapidly computes visibility by rendering blocker geometry into a 2D occlusion mask with correct occluder fusion. The response of an object to the lighting is found by integrating the visibility function at each of the vertices against the spherical harmonic functions and the BRDF. This yields transfer coefficients that are then multiplied by the lighting coefficients to obtain the final, shadowed exitant radiance. No precomputation is necessary and memory requirements are modest. The method supports both diffuse and glossy BRDFs.
@InProceedings{Kautz2004egsr,
author = {Jan Kautz and Jaakko Lehtinen and Timo Aila},
title = {Hemispherical Rasterization for Self-Shadowing of Dynamic Objects},
booktitle = {Proc. Eurographics Symposium on Rendering 2004},
pages = {179--184},
year = {2004},
publisher = {Eurographics Association},
}
Abstract-
@article{aila2004cga,
author = {Timo Aila and Ville Miettinen},
title = {dPVS: An Occlusion Culling System for Massive Dynamic Environments},
journal = {IEEE Computer Graphics and Applications},
volume = {24},
number = {2},
year = {2004},
pages = {86--97},
publisher = {IEEE Computer Society Press},
}
 |
Optimized Shadow Mapping Using the Stencil Buffer. Jukka Arvo and Timo Aila. Journal of Graphics Tools 8(3), 2003. Reprinted in The JGT Editors' Choice. Abstract Bibtex JGT page |
Shadow maps and shadow volumes are common techniques for computing real-time shadows. We optimize the performance of a hardware-accelerated shadow mapping algorithm by rasterizing the light frustum into the stencil buffer, in a manner similar to the shadow volume algorithm. The pixel shader code that performs shadow tests and illumination computations is applied only to the pixels that are inside the light frustum. We also use deferred shading to further limit the operations to visible pixels. Our technique can be easily plugged into existing applications, and is especially useful for dynamic scenes that contain several local light sources. In our test scenarios, the overall frame rate was up 2.2 times higher than for our comparison methods.
@article{Arvo2003jgt,
author = {Jukka Arvo and Timo Aila},
title = {Optimized Shadow Mapping Using the Stencil Buffer},
journal = {Journal of Graphics Tools},
year = {2003},
volume = {8},
number = {3},
pages = {23--32},
}
 |
Delay Streams for Graphics Hardware. Timo Aila, Ville Miettinen, and Petri Nordlund. ACM Transactions on Graphics 22(3) (SIGGRAPH 2003). Abstract Bibtex PDF Slides Fast Forward |
In causal processes decisions do not depend on future data. Many well-known problems, such as occlusion culling, order-independent transparency and edge antialiasing cannot be properly solved using the traditional causal rendering architectures, because future data may change the interpretation of current events.
We propose adding a delay stream between the vertex and pixel processing units. While a triangle resides in the delay stream, subsequent triangles generate occlusion information. As a result, the triangle may be culled by primitives that were submitted after it. We show two- to fourfold efficiency improvements in pixel processing and video memory bandwidth usage in common benchmark scenes. We also demonstrate how the memory requirements of order-independent transparency can be substantially reduced by using delay streams. Finally, we describe how discontinuity edges can be detected in hardware. Previously used heuristics for collapsing samples in adaptive supersampling are thus replaced by connectivity information.
@article{aila2003siggraph,
author = {Timo Aila and Ville Miettinen and Petri Nordlund},
title = {Delay Streams for Graphics Hardare},
journal = {ACM Trans. Graph.},
volume = {22},
number = {3},
year = {2003},
pages = {792--800},
publisher = {ACM Press},
}
This technical report is an addendum to the HPG2009 paper "Understanding the Efficiency of Ray Traversal on GPUs", and provides citable performance results for Kepler and Fermi architectures. We explain how to optimize the traversal and intersection kernels for these newer platforms, and what the important architectural limiters are. We plot the relative ray tracing performance between architecture generations against the available memory bandwidth and peak FLOPS, and demonstrate that ray tracing is still, even with incoherent rays and more complex scenes, almost entirely limited by the available FLOPS. We will also discuss two esoteric instructions, present in both Fermi and Kepler, and show that they can be safely used for faster acceleration structure traversal.
@techreport{Aila:Efficiency:NVIDIA:2012,
author = {Timo Aila and Samuli Laine and Tero Karras},
title = {Understanding the Efficiency of Ray Traversal on {GPU}s -- {K}epler and {F}ermi Addendum},
month = jun,
year = 2012,
institution = {NVIDIA Corporation},
type = {NVIDIA Technical Report},
number = {NVR-2012-02},
}
 |
Proc. Graphics Hardware 2007.
Mark Segal and Timo Aila (editors). [Publisher's site] |