Note
Click here to download the full example code
Compute RSA between DSMs¶
This example showcases the most basic version of RSA: computing the similarity between two DSMs. Then we continue with computing RSA between many DSMs efficiently.
# sphinx_gallery_thumbnail_number=2
# Import required packages
import pandas as pd
from matplotlib import pyplot as plt
import mne
import mne_rsa
MNE-Python contains a build-in data loader for the kiloword dataset, which is
used here as an example dataset. Since we only need the words shown during
the experiment, which are in the metadata, we can pass preload=False to
prevent MNE-Python from loading the EEG data, which is a nice speed gain.
data_path = mne.datasets.kiloword.data_path(verbose=True)
epochs = mne.read_epochs(data_path / 'kword_metadata-epo.fif')
# Show the metadata of 10 random epochs
epochs.metadata.sample(10)
Reading C:\Users\wmvan\mne_data\MNE-kiloword-data\kword_metadata-epo.fif ...
Isotrak not found
Found the data of interest:
t = -100.00 ... 920.00 ms
0 CTF compensation matrices available
Adding metadata with 8 columns
960 matching events found
No baseline correction applied
0 projection items activated
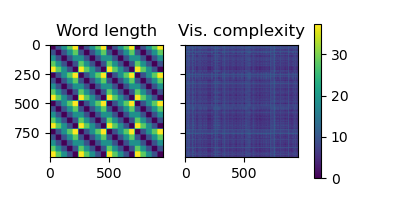
Compute DSMs based on word length and visual complexity.
metadata = epochs.metadata
dsm1 = mne_rsa.compute_dsm(metadata.NumberOfLetters, metric='euclidean')
dsm2 = mne_rsa.compute_dsm(metadata.VisualComplexity, metric='euclidean')
# Plot the DSMs
mne_rsa.plot_dsms([dsm1, dsm2], names=['Word length', 'Vis. complexity'])
<Figure size 400x200 with 3 Axes>
Perform RSA between the two DSMs using Spearman correlation
rsa_result = mne_rsa.rsa(dsm1, dsm2, metric='spearman')
print('RSA score:', rsa_result)
RSA score: 0.02643988328911863
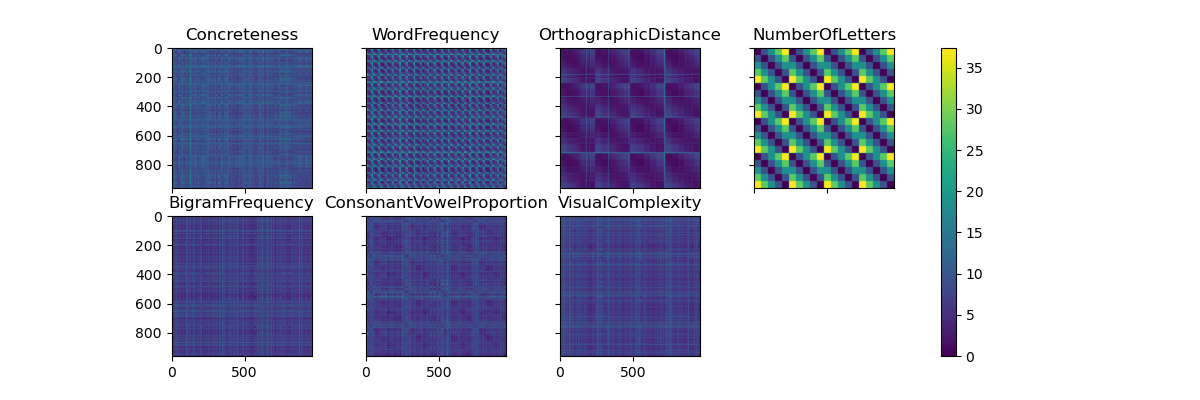
We can compute RSA between multiple DSMs by passing lists to the
mne_rsa.rsa() function.
# Create DSMs for each stimulus property
columns = metadata.columns[1:] # Skip the first column: WORD
dsms = [mne_rsa.compute_dsm(metadata[col], metric='euclidean')
for col in columns]
# Plot the DSMs
fig = mne_rsa.plot_dsms(dsms, names=columns, n_rows=2)
fig.set_size_inches(12, 4)
# Compute RSA between the first two DSMs (Concreteness and WordFrequency) and
# the others.
rsa_results = mne_rsa.rsa(dsms[:2], dsms[2:], metric='spearman')
# Pack the result into a Pandas DataFrame for easy viewing
print(pd.DataFrame(rsa_results, index=columns[:2], columns=columns[2:]))
OrthographicDistance NumberOfLetters ... ConsonantVowelProportion VisualComplexity
Concreteness 0.031064 0.026832 ... 0.005647 0.004263
WordFrequency 0.058385 0.013607 ... -0.003850 -0.009620
[2 rows x 5 columns]
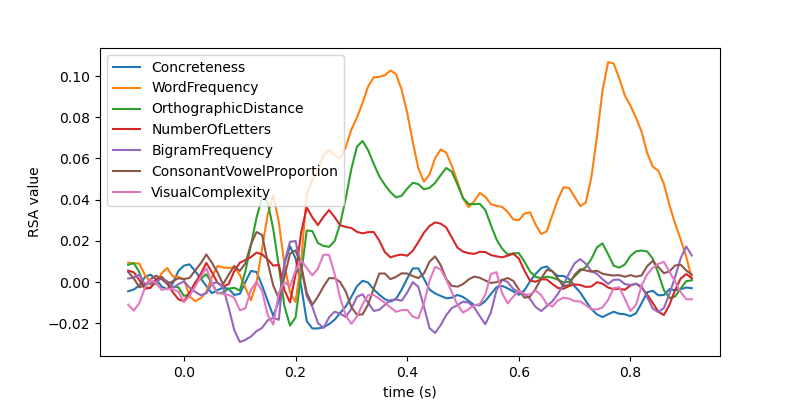
What if we have many DSMs? The mne_rsa.rsa() function is optimized for
the case where the first parameter (the “data” DSMs) is a large list of DSMs
and the second parameter (the “model” DSMs) is a smaller list. To save
memory, you can also pass generators instead of lists.
Let’s create a generator that creates DSMs for each time-point in the EEG
data and compute the RSA between those DSMs and all the “model” DSMs we
computed above. This is a basic example of using a “searchlight” and in other
examples, you can learn how to use the searchlight generator to
build more advanced searchlights. However, since this is such a simple case,
it is educational to construct the generator manually.
The RSA computation will take some time. Therefore, we pass a few extra
parameters to mne_rsa.rsa() to enable some improvements. First, the
verbose=True enables a progress bar. However, since we are using a
generator, the progress bar cannot automatically infer how many DSMs there
will be. Hence, we provide this information explicitly using the
n_data_dsms parameter. Finally, depending on how many CPUs you have on
your system, consider increasing the n_jobs parameter to parallelize the
computation over multiple CPUs.
epochs.resample(100) # Downsample to speed things up for this example
eeg_data = epochs.get_data()
n_trials, n_sensors, n_times = eeg_data.shape
def generate_eeg_dsms():
"""Generate DSMs for each time sample."""
for i in range(n_times):
yield mne_rsa.compute_dsm(eeg_data[:, :, i], metric='correlation')
rsa_results = mne_rsa.rsa(generate_eeg_dsms(), dsms, metric='spearman',
verbose=True, n_data_dsms=n_times, n_jobs=1)
# Plot the RSA values over time using standard matplotlib commands
plt.figure(figsize=(8, 4))
plt.plot(epochs.times, rsa_results)
plt.xlabel('time (s)')
plt.ylabel('RSA value')
plt.legend(columns)
0%| | 0/102 [00:00<?, ?DSM/s]
1%|6 | 1/102 [00:01<01:42, 1.02s/DSM]
2%|#2 | 2/102 [00:02<01:43, 1.04s/DSM]
3%|#8 | 3/102 [00:03<01:41, 1.02s/DSM]
4%|##4 | 4/102 [00:04<01:39, 1.01s/DSM]
5%|### | 5/102 [00:05<01:38, 1.01s/DSM]
6%|###7 | 6/102 [00:06<01:37, 1.01s/DSM]
7%|####3 | 7/102 [00:07<01:37, 1.03s/DSM]
8%|####9 | 8/102 [00:08<01:36, 1.03s/DSM]
9%|#####5 | 9/102 [00:09<01:34, 1.02s/DSM]
10%|###### | 10/102 [00:10<01:34, 1.03s/DSM]
11%|######6 | 11/102 [00:11<01:33, 1.03s/DSM]
12%|#######2 | 12/102 [00:12<01:34, 1.05s/DSM]
13%|#######9 | 13/102 [00:13<01:32, 1.04s/DSM]
14%|########5 | 14/102 [00:14<01:30, 1.02s/DSM]
15%|#########1 | 15/102 [00:15<01:30, 1.04s/DSM]
16%|#########7 | 16/102 [00:16<01:30, 1.05s/DSM]
17%|##########3 | 17/102 [00:17<01:29, 1.05s/DSM]
18%|##########9 | 18/102 [00:18<01:28, 1.05s/DSM]
19%|###########5 | 19/102 [00:19<01:26, 1.04s/DSM]
20%|############1 | 20/102 [00:20<01:27, 1.07s/DSM]
21%|############7 | 21/102 [00:21<01:25, 1.06s/DSM]
22%|#############3 | 22/102 [00:22<01:25, 1.06s/DSM]
23%|#############9 | 23/102 [00:23<01:22, 1.04s/DSM]
24%|##############5 | 24/102 [00:24<01:21, 1.04s/DSM]
25%|###############1 | 25/102 [00:26<01:21, 1.06s/DSM]
25%|###############8 | 26/102 [00:27<01:19, 1.05s/DSM]
26%|################4 | 27/102 [00:28<01:17, 1.03s/DSM]
27%|################# | 28/102 [00:29<01:16, 1.03s/DSM]
28%|#################6 | 29/102 [00:30<01:15, 1.03s/DSM]
29%|##################2 | 30/102 [00:31<01:16, 1.06s/DSM]
30%|##################8 | 31/102 [00:32<01:15, 1.07s/DSM]
31%|###################4 | 32/102 [00:33<01:13, 1.05s/DSM]
32%|#################### | 33/102 [00:34<01:11, 1.03s/DSM]
33%|####################6 | 34/102 [00:35<01:10, 1.04s/DSM]
34%|#####################2 | 35/102 [00:36<01:10, 1.05s/DSM]
35%|#####################8 | 36/102 [00:37<01:09, 1.05s/DSM]
36%|######################4 | 37/102 [00:38<01:07, 1.04s/DSM]
37%|####################### | 38/102 [00:39<01:05, 1.03s/DSM]
38%|#######################7 | 39/102 [00:40<01:06, 1.06s/DSM]
39%|########################3 | 40/102 [00:41<01:06, 1.07s/DSM]
40%|########################9 | 41/102 [00:42<01:06, 1.08s/DSM]
41%|#########################5 | 42/102 [00:44<01:08, 1.14s/DSM]
42%|##########################1 | 43/102 [00:45<01:06, 1.12s/DSM]
43%|##########################7 | 44/102 [00:46<01:04, 1.11s/DSM]
44%|###########################3 | 45/102 [00:47<01:03, 1.11s/DSM]
45%|###########################9 | 46/102 [00:48<01:02, 1.11s/DSM]
46%|############################5 | 47/102 [00:49<01:02, 1.13s/DSM]
47%|#############################1 | 48/102 [00:50<01:01, 1.14s/DSM]
48%|#############################7 | 49/102 [00:52<01:01, 1.15s/DSM]
49%|##############################3 | 50/102 [00:53<00:59, 1.14s/DSM]
50%|############################### | 51/102 [00:54<01:00, 1.19s/DSM]
51%|###############################6 | 52/102 [00:55<00:58, 1.17s/DSM]
52%|################################2 | 53/102 [00:56<00:58, 1.19s/DSM]
53%|################################8 | 54/102 [00:57<00:55, 1.15s/DSM]
54%|#################################4 | 55/102 [00:58<00:51, 1.10s/DSM]
55%|################################## | 56/102 [00:59<00:49, 1.07s/DSM]
56%|##################################6 | 57/102 [01:00<00:47, 1.06s/DSM]
57%|###################################2 | 58/102 [01:01<00:45, 1.04s/DSM]
58%|###################################8 | 59/102 [01:02<00:44, 1.03s/DSM]
59%|####################################4 | 60/102 [01:03<00:42, 1.01s/DSM]
60%|##################################### | 61/102 [01:04<00:41, 1.01s/DSM]
61%|#####################################6 | 62/102 [01:05<00:40, 1.01s/DSM]
62%|######################################2 | 63/102 [01:06<00:39, 1.01s/DSM]
63%|######################################9 | 64/102 [01:07<00:38, 1.01s/DSM]
64%|#######################################5 | 65/102 [01:08<00:37, 1.00s/DSM]
65%|########################################1 | 66/102 [01:09<00:35, 1.01DSM/s]
66%|########################################7 | 67/102 [01:10<00:34, 1.00DSM/s]
67%|#########################################3 | 68/102 [01:11<00:34, 1.02s/DSM]
68%|#########################################9 | 69/102 [01:12<00:33, 1.02s/DSM]
69%|##########################################5 | 70/102 [01:13<00:31, 1.01DSM/s]
70%|###########################################1 | 71/102 [01:14<00:30, 1.02DSM/s]
71%|###########################################7 | 72/102 [01:15<00:30, 1.01s/DSM]
72%|############################################3 | 73/102 [01:16<00:29, 1.01s/DSM]
73%|############################################9 | 74/102 [01:17<00:28, 1.01s/DSM]
74%|#############################################5 | 75/102 [01:18<00:26, 1.01DSM/s]
75%|##############################################1 | 76/102 [01:19<00:25, 1.02DSM/s]
75%|##############################################8 | 77/102 [01:20<00:25, 1.00s/DSM]
76%|###############################################4 | 78/102 [01:21<00:24, 1.02s/DSM]
77%|################################################ | 79/102 [01:22<00:23, 1.01s/DSM]
78%|################################################6 | 80/102 [01:23<00:21, 1.01DSM/s]
79%|#################################################2 | 81/102 [01:24<00:20, 1.00DSM/s]
80%|#################################################8 | 82/102 [01:25<00:20, 1.02s/DSM]
81%|##################################################4 | 83/102 [01:26<00:19, 1.01s/DSM]
82%|################################################### | 84/102 [01:27<00:17, 1.00DSM/s]
83%|###################################################6 | 85/102 [01:28<00:16, 1.01DSM/s]
84%|####################################################2 | 86/102 [01:29<00:15, 1.02DSM/s]
85%|####################################################8 | 87/102 [01:30<00:15, 1.01s/DSM]
86%|#####################################################4 | 88/102 [01:32<00:14, 1.07s/DSM]
87%|###################################################### | 89/102 [01:33<00:13, 1.08s/DSM]
88%|######################################################7 | 90/102 [01:34<00:12, 1.07s/DSM]
89%|#######################################################3 | 91/102 [01:35<00:11, 1.06s/DSM]
90%|#######################################################9 | 92/102 [01:36<00:10, 1.06s/DSM]
91%|########################################################5 | 93/102 [01:37<00:09, 1.05s/DSM]
92%|#########################################################1 | 94/102 [01:38<00:08, 1.01s/DSM]
93%|#########################################################7 | 95/102 [01:39<00:07, 1.00s/DSM]
94%|##########################################################3 | 96/102 [01:40<00:06, 1.02s/DSM]
95%|##########################################################9 | 97/102 [01:41<00:05, 1.03s/DSM]
96%|###########################################################5 | 98/102 [01:42<00:04, 1.04s/DSM]
97%|############################################################1 | 99/102 [01:43<00:03, 1.03s/DSM]
98%|###########################################################8 | 100/102 [01:44<00:02, 1.03s/DSM]
99%|############################################################4| 101/102 [01:45<00:01, 1.03s/DSM]
100%|#############################################################| 102/102 [01:46<00:00, 1.03s/DSM]
100%|#############################################################| 102/102 [01:46<00:00, 1.04s/DSM]
<matplotlib.legend.Legend object at 0x00000267D2A7C6A0>
Total running time of the script: ( 1 minutes 51.260 seconds)