Note
Click here to download the full example code
Construct a model DSM¶
This example shows how to create DSMs from arbitrary data. A common use case for this is to construct a “model” DSM to RSA against the brain data. In this example, we will create a DSM based on the length of the words shown during an EEG experiment.
# Import required packages
import mne
import mne_rsa
MNE-Python contains a build-in data loader for the kiloword dataset, which is
used here as an example dataset. Since we only need the words shown during
the experiment, which are in the metadata, we can pass preload=False to
prevent MNE-Python from loading the EEG data, which is a nice speed gain.
data_path = mne.datasets.kiloword.data_path(verbose=True)
epochs = mne.read_epochs(data_path / 'kword_metadata-epo.fif', preload=False)
# Show the metadata of 10 random epochs
print(epochs.metadata.sample(10))
Reading C:\Users\wmvan\mne_data\MNE-kiloword-data\kword_metadata-epo.fif ...
Isotrak not found
Found the data of interest:
t = -100.00 ... 920.00 ms
0 CTF compensation matrices available
Adding metadata with 8 columns
960 matching events found
No baseline correction applied
0 projection items activated
WORD Concreteness ... ConsonantVowelProportion VisualComplexity
362 hazard 3.45 ... 0.666667 68.943826
690 interior 4.20 ... 0.500000 53.360692
332 poesy 5.00 ... 0.400000 74.259702
552 stern 3.65 ... 0.800000 60.215695
692 doctrine 2.95 ... 0.625000 61.243776
67 crowd 5.55 ... 0.800000 71.864295
671 fluency 2.85 ... 0.571429 60.572977
375 mentor 4.45 ... 0.666667 66.052349
25 golf 5.70 ... 0.750000 63.026557
617 oracle 3.60 ... 0.500000 61.460712
[10 rows x 8 columns]
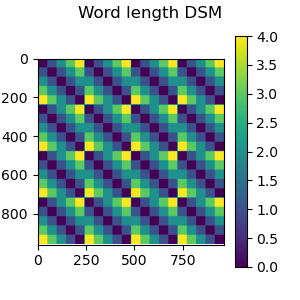
Now we are ready to create the “model” DSM, which will encode the difference in length between the words shown during the experiment.
dsm = mne_rsa.compute_dsm(epochs.metadata.NumberOfLetters, metric='euclidean')
# Plot the DSM
fig = mne_rsa.plot_dsms(dsm, title='Word length DSM')
fig.set_size_inches(3, 3) # Make figure a little bigger to show axis properly
Total running time of the script: ( 0 minutes 0.515 seconds)