Note
Go to the end to download the full example code.
Tutorial part 1: RSA on sensor-level MEG data#
In this tutorial, we will perform sensor-level RSA analysis on MEG data.
We will explore how representational similarity analysis (RSA) can be used to study the neural representational code within visual cortex. We will start with performing RSA on the sensor level data, followed by source level and finally we will perform group level statistical analysis. Along the way, we will encounter many of the functions and classes offered by MNE-RSA, which will always be presented in the form of links to the API Documentation which you are encouraged to explore.
The dataset we will be working with today is the MEG data of the Wakeman & Nelson (2015) “faces” dataset. During this experiment, participants were presented with a series of images, containing:
Faces of famous people that the participants likely knew
Faces of people that the participants likely did not know
Scrambled faces: the images were cut-up and randomly put together again
As a first step, you need to download and extract the dataset: rsa-data.zip.
You can either do this by executing the cell below, or you can do so manually. In any
case, make sure that the data_path variable points to where you have extracted the
rsa-data.zip
file to.
# ruff: noqa: E402
# sphinx_gallery_thumbnail_number=8
import os
import pooch
# Download and unzip the data
pooch.retrieve(
url="https://github.com/wmvanvliet/neuroscience_tutorials/releases/download/2/rsa-data.zip",
known_hash="md5:859c0684dd25f8b82d011840725cbef6",
progressbar=True,
processor=pooch.Unzip(members=["data"], extract_dir=os.getcwd()),
)
# Set this to where you've extracted `rsa-data.zip` to
data_path = "data"
A representational code for the stimuli#
Let’s start by taking a look at the stimuli that were presented during the experiment.
They reside in the stimuli folder for you as .bmp image files. The Python
Imaging Library (PIL) can open them and we can use matplotlib to display them.
import matplotlib.pyplot as plt
from PIL import Image
# Show the first "famous" face and the first "scrambled" face
img_famous = Image.open(f"{data_path}/stimuli/f001.bmp")
img_scrambled = Image.open(f"{data_path}/stimuli/s001.bmp")
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].imshow(img_famous, cmap="gray")
axes[0].set_title(f"Famous face: {img_famous.width} x {img_famous.height} pixels")
axes[1].imshow(img_scrambled, cmap="gray")
axes[1].set_title(
f"Scrambled face: {img_scrambled.width} x {img_scrambled.height} pixels"
)
axes[0].axis("off")
axes[1].axis("off")
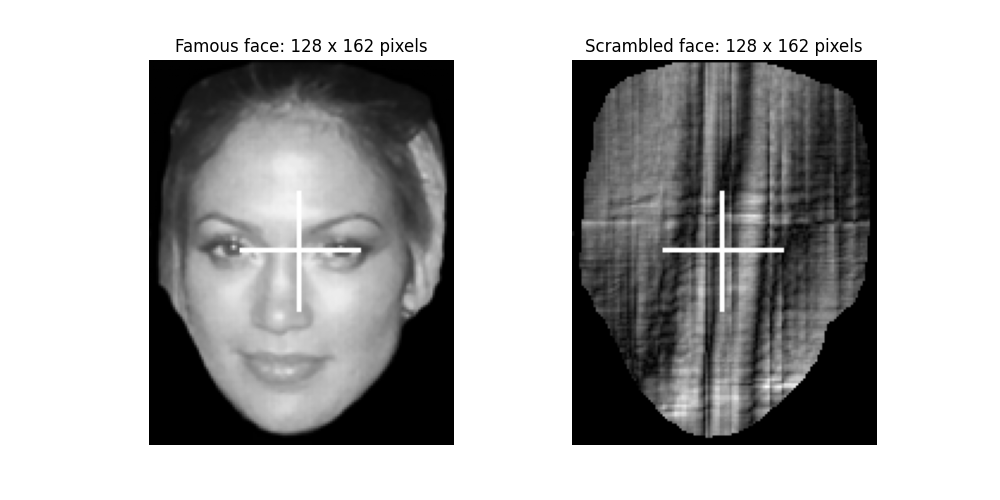
(np.float64(-0.5), np.float64(127.5), np.float64(161.5), np.float64(-0.5))
Loaded like this, the stimuli are in a representational space defined by their pixels. Each image is represented by 128 x 162 = 20736 values between 0 (black) and 255 (white). Let’s create a Representational Dissimilarity Matrix (RDM) where images are compared based on the difference between their pixels. To get the pixels of an image, you can convert it to a NumPy array like this:
import numpy as np
pixels_famous = np.array(img_famous)
pixels_scrambled = np.array(img_scrambled)
print("Shape of the pixel array for the famous face:", pixels_famous.shape)
print("Shape of the pixel array for the scrambled face:", pixels_scrambled.shape)
Shape of the pixel array for the famous face: (162, 128)
Shape of the pixel array for the scrambled face: (162, 128)
We can now compute the “dissimilarity” between the two images, based on their pixels. For this, we need to decide on a metric to use. The default metric used in the original publication (Kiegeskorte et al. 2008) was Pearson Correlation, so let’s use that. Of course, correlation is a metric of similarity and we want a metric of dissimilarity. Let’s make it easy on ourselves and just do \(1 - r\).
from scipy.stats import pearsonr
similarity, _ = pearsonr(pixels_famous.flatten(), pixels_scrambled.flatten())
dissimilarity = 1 - similarity
print(
"The dissimilarity between the pixels of the famous and scrambled faces is:",
dissimilarity,
)
The dissimilarity between the pixels of the famous and scrambled faces is: 0.4176835093510478
To construct the full RDM, we need to do this for all pairs of images. In the cell
below, we make a list of all image files and load all of them (there are 450), convert
them to NumPy arrays and concatenate them all together in a single big array called
pixels of shape n_images x width x height.
There are 450 images to read.
The dimensions of the `pixel` array are: (450, 162, 128)
Your first RDM#
Now that you have all the images loaded in, computing the pairwise dissimilarities is
a matter of looping over them and computing correlations. We could do this manually,
but we can make our life a lot easier by using MNE-RSA’s mne_rsa.compute_rdm()
function. It wants the big matrix as input and also takes a metric parameter to
select which dissimilarity metric to use. Setting it to metric="correlation",
which is also the default by the way, will make it use (1 - Pearson correlation) as a
metric like we did manually above.
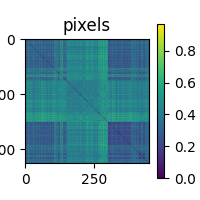
<Figure size 200x200 with 2 Axes>
Staring deeply into this RDM will reveal to you which images belonged to the “scrambled faces” class, as those pixels are quite different from the actual faces and each other. We also see that for some reason, the famous faces are a little more alike than the unknown faces.
The RDM is symmetric along the diagonal, which is all zeros. Take a moment to ponder why that would be.
Note
The mne_rsa.compute_rdm() function is a wrapper around
scipy.spatial.distance.pdist(). This means that all the metrics supported by
pdist() are also valid for
mne_rsa.compute_rdm(). This also means that in MNE-RSA, the native format for
an RDM is the so-called “condensed” form. Since RDMs are symmetric, only the upper
triangle is stored. The scipy.spatial.distance.squareform() function can be
used to go from a square matrix to its condensed form and back.
Your second RDM#
There are many sensible representations possible for images. One intriguing one is to create them using convolutional neural networks (CNNs). For example, there is the FaceNet model by Schroff et al. (2015) that can generate high-level representations, such that different photos of the same face have similar representations. I have run the stimulus images through FaceNet and recorded the generated embeddings for you to use:
store = np.load(f"{data_path}/stimuli/facenet_embeddings.npz")
filenames = store["filenames"]
embeddings = store["embeddings"]
print(
"For each of the 450 images, the embedding is a vector of length 512:",
embeddings.shape,
)
facenet_rdm = compute_rdm(embeddings)
For each of the 450 images, the embedding is a vector of length 512: (450, 512)
Lets plot both RDMs side-by-side:
plot_rdms([pixel_rdm, facenet_rdm], names=["pixels", "facenet"])
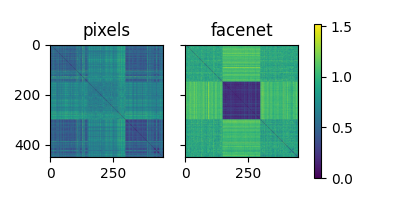
<Figure size 400x200 with 3 Axes>
A look at the brain data#
We’ve seen how we can create RDMs using properties of the images or embeddings generated by a model. Now it’s time to see how we create RDMs based on the MEG data. For that, we first load the epochs from a single participant.
import mne
epochs = mne.read_epochs(f"{data_path}/sub-02/sub-02-epo.fif")
epochs
Each epoch corresponds to the presentation of an image, and the signal across the sensors over time can be used as the neural representation of that image. Hence, one could make a neural RDM, of for example the gradiometers in the time window 100 to 200 ms after stimulus onset, like this:
neural_rdm = compute_rdm(epochs.copy().pick("grad").crop(0.1, 0.2).get_data())
plot_rdms(neural_rdm)
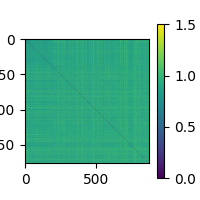
<Figure size 200x200 with 2 Axes>
To compute RSA scores, we want to compare the resulting neural RDM with the RDMs we’ve created earlier. However, if we inspect the neural RDM closely, we see that its rows and column don’t line up with those of the previous RDMs. There are too many (879 vs. 450) and they are in the wrong order. Making sure that the RDMs match is an important and sometimes tricky part of RSA.
To help us out, a useful feature of MNE-Python is that epochs have an associated
mne.Epochs.metadata field. This metadata is a pandas.DataFrame where
each row contains information about the corresponding epoch. The epochs in this
tutorial come with some useful .metadata already:
epochs.metadata
While the trigger codes only indicate what type of stimulus was shown, the file
column of the metadata tells us the exact image. Couple of challenges here: the
stimuli where shown in a random order, stimuli were repeated twice during the
experiment, and some epochs were dropped during preprocessing so not every image is
necessarily present twice in the epochs data. 😩
Luckily, MNE-RSA has a way to make our lives easier. Let’s take a look at the
mne_rsa.rdm_epochs() function, the Swiss army knife for computing RDMs from an
MNE-Python mne.Epochs object.
In MNE-Python tradition, the function has a lot of parameters, but all-but-one have a default so you only have to specify the ones that are relevant to you. For example, to redo the neural RDM we created above, we could do something like:
from mne_rsa import rdm_epochs
neural_rdm_gen = rdm_epochs(epochs, tmin=0.1, tmax=0.2)
# `rdm_epochs` returns a generator of RDMs
# unpacking the first (and only) RDM from the generator
neural_rdm = next(neural_rdm_gen)
plot_rdms(neural_rdm)
<Figure size 200x200 with 2 Axes>
Take note that mne_rsa.rdm_epochs() returns a generator of RDMs. This is because one of the main
use-cases for MNE-RSA is to produce RDMs using sliding windows (in time and also in
space), which can produce a large amount of RDMs that can take up a lot of memory of
you’re not careful.
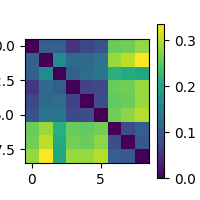
Alignment between model and data RDM ordering#
Looking at the neural RDM above, something is clearly different from the
one we made before. This one has 9 rows and columns. Closely inspecting
the docstring of mne_rsa.rdm_epochs reveals that it is the labels
parameter that is responsible for this:
labels : list | None
For each epoch, a label that identifies the item to which it corresponds.
Multiple epochs may correspond to the same item, in which case they should have
the same label and will either be averaged when computing the data RDM
(``n_folds=1``) or used for cross-validation (``n_folds>1``). Labels may be of
any python type that can be compared with ``==`` (int, float, string, tuple,
etc). By default (``None``), the epochs event codes are used as labels.
Instead of producing one row per epoch, mne_rsa.rdm_epochs() produced one row
per event type, averaging across epochs of the same type before computing
dissimilarity. This is not quite what we want though. If we want to match
pixel_rdm and facenet_rdm, we want every single one of the 450 images to be
its own stimulus type. We can achieve this by setting the labels parameter of
mne_rsa.rdm_epochs() to a list that assigns each of the 879 epochs to a label
that indicates which image was shown. An image is identified by its filename, and the
epochs.metadata.file column contains the filenames corresponding to the epochs,
so let’s use that.
neural_rdm = next(rdm_epochs(epochs, labels=epochs.metadata.file, tmin=0.1, tmax=0.2))
# This plots your RDM
plot_rdms(neural_rdm)
<Figure size 200x200 with 2 Axes>
The cell below will compure RSA between the neural RDM and the pixel and FaceNet RDMs we created earlier. The RSA score will be the Spearman correlation between the RDMs, which is the default metric used in the original RSA paper.
from mne_rsa import rsa
rsa_pixel = rsa(neural_rdm, pixel_rdm, metric="spearman")
rsa_facenet = rsa(neural_rdm, facenet_rdm, metric="spearman")
print("RSA score between neural RDM and pixel RDM:", rsa_pixel)
print("RSA score between neural RDM and FaceNet RDM:", rsa_facenet)
RSA score between neural RDM and pixel RDM: 0.07869920694906636
RSA score between neural RDM and FaceNet RDM: 0.07529582461337744
Slippin’ and slidin’ across time#
The neural representation of a stimulus is different across brain regions and evolves over time. For example, we would expect that the pixel RDM would be more similar to a neural RDM that we computed across the visual cortex at an early time point, and that the FaceNET RDM might be more similar to a neural RDM that we computed at a later time point.
For the remainder of this tutorial, we’ll restrict the epochs to
only contain the sensors over the left occipital cortex.
Warning
Just because we select sensors over a certain brain region, does not mean the magnetic fields originate from that region. This is especially true for magnetometers. To make it a bit more accurate, we only select gradiometers.
picks = mne.channels.read_vectorview_selection("Left-occipital")
picks = ["".join(p.split(" ")) for p in picks]
epochs.pick(picks).pick("grad").crop(-0.1, 1)
In the cell below, we use mne_rsa.rdm_epochs() to compute RDMs using a sliding
window by setting the temporal_radius parameter to 0.1 seconds. We use the
entire time range (tmin=None and tmax=None) and leave the result as a
generator (so no next() calls).
neural_rdms_gen = rdm_epochs(epochs, labels=epochs.metadata.file, temporal_radius=0.1)
And now we can consume the generator (with a nice progress bar) and plot a few of the generated RDMs:
from tqdm import tqdm
times = epochs.times[(epochs.times >= 0) & (epochs.times <= 0.9)]
neural_rdms_list = list(tqdm(neural_rdms_gen, total=len(times)))
plot_rdms(neural_rdms_list[::10], names=[f"t={t:.2f}" for t in times[::10]])

0%| | 0/199 [00:00<?, ?it/s]
1%|▎ | 1/199 [00:00<00:54, 3.63it/s]
2%|▉ | 3/199 [00:00<00:26, 7.28it/s]
3%|█▋ | 5/199 [00:00<00:21, 8.92it/s]
4%|██▎ | 7/199 [00:00<00:19, 9.61it/s]
5%|██▉ | 9/199 [00:00<00:18, 10.06it/s]
6%|███▌ | 11/199 [00:01<00:17, 10.51it/s]
7%|████▏ | 13/199 [00:01<00:17, 10.34it/s]
8%|████▊ | 15/199 [00:01<00:17, 10.41it/s]
9%|█████▍ | 17/199 [00:01<00:17, 10.64it/s]
10%|██████ | 19/199 [00:01<00:17, 10.50it/s]
11%|██████▊ | 21/199 [00:02<00:17, 10.14it/s]
12%|███████▍ | 23/199 [00:02<00:16, 10.36it/s]
13%|████████ | 25/199 [00:02<00:16, 10.43it/s]
14%|████████▋ | 27/199 [00:02<00:16, 10.65it/s]
15%|█████████▎ | 29/199 [00:02<00:15, 10.80it/s]
16%|█████████▉ | 31/199 [00:03<00:15, 11.01it/s]
17%|██████████▌ | 33/199 [00:03<00:14, 11.11it/s]
18%|███████████▎ | 35/199 [00:03<00:14, 11.21it/s]
19%|███████████▉ | 37/199 [00:03<00:14, 11.14it/s]
20%|████████████▌ | 39/199 [00:03<00:14, 11.24it/s]
21%|█████████████▏ | 41/199 [00:03<00:13, 11.45it/s]
22%|█████████████▊ | 43/199 [00:04<00:13, 11.39it/s]
23%|██████████████▍ | 45/199 [00:04<00:13, 11.41it/s]
24%|███████████████ | 47/199 [00:04<00:13, 11.39it/s]
25%|███████████████▊ | 49/199 [00:04<00:13, 11.32it/s]
26%|████████████████▍ | 51/199 [00:04<00:13, 11.12it/s]
27%|█████████████████ | 53/199 [00:05<00:13, 11.13it/s]
28%|█████████████████▋ | 55/199 [00:05<00:12, 11.17it/s]
29%|██████████████████▎ | 57/199 [00:05<00:12, 11.21it/s]
30%|██████████████████▉ | 59/199 [00:05<00:12, 10.97it/s]
31%|███████████████████▌ | 61/199 [00:05<00:12, 11.23it/s]
32%|████████████████████▎ | 63/199 [00:05<00:12, 11.22it/s]
33%|████████████████████▉ | 65/199 [00:06<00:11, 11.24it/s]
34%|█████████████████████▌ | 67/199 [00:06<00:11, 11.28it/s]
35%|██████████████████████▏ | 69/199 [00:06<00:11, 11.46it/s]
36%|██████████████████████▊ | 71/199 [00:06<00:11, 11.63it/s]
37%|███████████████████████▍ | 73/199 [00:06<00:10, 11.69it/s]
38%|████████████████████████ | 75/199 [00:06<00:10, 11.48it/s]
39%|████████████████████████▊ | 77/199 [00:07<00:10, 11.37it/s]
40%|█████████████████████████▍ | 79/199 [00:07<00:10, 11.40it/s]
41%|██████████████████████████ | 81/199 [00:07<00:10, 11.52it/s]
42%|██████████████████████████▋ | 83/199 [00:07<00:10, 11.45it/s]
43%|███████████████████████████▎ | 85/199 [00:07<00:10, 11.39it/s]
44%|███████████████████████████▉ | 87/199 [00:07<00:09, 11.38it/s]
45%|████████████████████████████▌ | 89/199 [00:08<00:09, 11.31it/s]
46%|█████████████████████████████▎ | 91/199 [00:08<00:11, 9.47it/s]
46%|█████████████████████████████▌ | 92/199 [00:08<00:13, 8.20it/s]
47%|█████████████████████████████▉ | 93/199 [00:08<00:12, 8.29it/s]
47%|██████████████████████████████▏ | 94/199 [00:08<00:12, 8.39it/s]
48%|██████████████████████████████▌ | 95/199 [00:08<00:12, 8.59it/s]
48%|██████████████████████████████▊ | 96/199 [00:09<00:12, 8.58it/s]
49%|███████████████████████████████▏ | 97/199 [00:09<00:11, 8.66it/s]
50%|███████████████████████████████▊ | 99/199 [00:09<00:10, 9.68it/s]
51%|███████████████████████████████▉ | 101/199 [00:09<00:09, 10.24it/s]
52%|████████████████████████████████▌ | 103/199 [00:09<00:09, 10.47it/s]
53%|█████████████████████████████████▏ | 105/199 [00:09<00:09, 10.44it/s]
54%|█████████████████████████████████▊ | 107/199 [00:10<00:08, 10.66it/s]
55%|██████████████████████████████████▌ | 109/199 [00:10<00:08, 10.84it/s]
56%|███████████████████████████████████▏ | 111/199 [00:10<00:08, 10.97it/s]
57%|███████████████████████████████████▊ | 113/199 [00:10<00:07, 10.98it/s]
58%|████████████████████████████████████▍ | 115/199 [00:10<00:07, 10.91it/s]
59%|█████████████████████████████████████ | 117/199 [00:11<00:07, 10.89it/s]
60%|█████████████████████████████████████▋ | 119/199 [00:11<00:07, 10.90it/s]
61%|██████████████████████████████████████▎ | 121/199 [00:11<00:07, 9.95it/s]
62%|██████████████████████████████████████▉ | 123/199 [00:11<00:07, 10.23it/s]
63%|███████████████████████████████████████▌ | 125/199 [00:11<00:07, 10.38it/s]
64%|████████████████████████████████████████▏ | 127/199 [00:12<00:07, 9.42it/s]
65%|████████████████████████████████████████▊ | 129/199 [00:12<00:07, 9.78it/s]
66%|█████████████████████████████████████████▍ | 131/199 [00:12<00:06, 10.12it/s]
67%|██████████████████████████████████████████ | 133/199 [00:12<00:06, 10.43it/s]
68%|██████████████████████████████████████████▋ | 135/199 [00:12<00:06, 10.56it/s]
69%|███████████████████████████████████████████▎ | 137/199 [00:12<00:05, 10.76it/s]
70%|████████████████████████████████████████████ | 139/199 [00:13<00:06, 9.85it/s]
71%|████████████████████████████████████████████▋ | 141/199 [00:13<00:06, 8.95it/s]
71%|████████████████████████████████████████████▉ | 142/199 [00:13<00:06, 8.41it/s]
72%|█████████████████████████████████████████████▎ | 143/199 [00:13<00:06, 8.25it/s]
72%|█████████████████████████████████████████████▌ | 144/199 [00:13<00:06, 8.47it/s]
73%|█████████████████████████████████████████████▉ | 145/199 [00:14<00:06, 7.81it/s]
73%|██████████████████████████████████████████████▏ | 146/199 [00:14<00:06, 7.88it/s]
74%|██████████████████████████████████████████████▊ | 148/199 [00:14<00:05, 8.87it/s]
75%|███████████████████████████████████████████████▍ | 150/199 [00:14<00:05, 9.53it/s]
76%|████████████████████████████████████████████████ | 152/199 [00:14<00:04, 10.06it/s]
77%|████████████████████████████████████████████████▍ | 153/199 [00:14<00:05, 9.05it/s]
77%|████████████████████████████████████████████████▊ | 154/199 [00:14<00:04, 9.13it/s]
78%|█████████████████████████████████████████████████ | 155/199 [00:15<00:04, 9.31it/s]
78%|█████████████████████████████████████████████████▍ | 156/199 [00:15<00:04, 9.45it/s]
79%|██████████████████████████████████████████████████ | 158/199 [00:15<00:04, 9.74it/s]
80%|██████████████████████████████████████████████████▎ | 159/199 [00:15<00:04, 8.97it/s]
81%|██████████████████████████████████████████████████▉ | 161/199 [00:15<00:03, 9.67it/s]
82%|███████████████████████████████████████████████████▌ | 163/199 [00:15<00:03, 9.96it/s]
83%|████████████████████████████████████████████████████▏ | 165/199 [00:16<00:03, 9.53it/s]
83%|████████████████████████████████████████████████████▌ | 166/199 [00:16<00:03, 9.12it/s]
84%|█████████████████████████████████████████████████████▏ | 168/199 [00:16<00:03, 9.29it/s]
85%|█████████████████████████████████████████████████████▌ | 169/199 [00:16<00:03, 9.41it/s]
85%|█████████████████████████████████████████████████████▊ | 170/199 [00:16<00:03, 9.52it/s]
86%|██████████████████████████████████████████████████████▏ | 171/199 [00:16<00:02, 9.52it/s]
87%|██████████████████████████████████████████████████████▊ | 173/199 [00:16<00:02, 10.03it/s]
88%|███████████████████████████████████████████████████████▍ | 175/199 [00:17<00:02, 10.30it/s]
89%|████████████████████████████████████████████████████████ | 177/199 [00:17<00:02, 10.13it/s]
90%|████████████████████████████████████████████████████████▋ | 179/199 [00:17<00:01, 10.47it/s]
91%|█████████████████████████████████████████████████████████▎ | 181/199 [00:17<00:01, 10.78it/s]
92%|█████████████████████████████████████████████████████████▉ | 183/199 [00:17<00:01, 11.10it/s]
93%|██████████████████████████████████████████████████████████▌ | 185/199 [00:18<00:01, 9.99it/s]
94%|███████████████████████████████████████████████████████████▏ | 187/199 [00:18<00:01, 9.81it/s]
94%|███████████████████████████████████████████████████████████▌ | 188/199 [00:18<00:01, 9.80it/s]
95%|████████████████████████████████████████████████████████████▏ | 190/199 [00:18<00:00, 10.12it/s]
96%|████████████████████████████████████████████████████████████▊ | 192/199 [00:18<00:00, 9.02it/s]
97%|█████████████████████████████████████████████████████████████▍ | 194/199 [00:19<00:00, 9.39it/s]
98%|██████████████████████████████████████████████████████████████ | 196/199 [00:19<00:00, 9.91it/s]
99%|██████████████████████████████████████████████████████████████▋| 198/199 [00:19<00:00, 9.60it/s]
100%|███████████████████████████████████████████████████████████████| 199/199 [00:19<00:00, 10.16it/s]
<Figure size 4000x200 with 21 Axes>
Putting it altogether for sensor-level RSA#
Now all that is left to do is compute RSA scored between the neural RDMs you’ve just
created and the pixel and FaceNet RDMs. We could do this using the
mne_rsa.rsa_gen() function, but I’d rather directly show you the
mne_rsa.rsa_epochs() function that combines computing the neural RDMs with
computing the RSA scores.
The signature of mne_rsa.rsa_epochs() is very similar to that of
mne_rsa.rdm_epochs() The main difference is that we also give it the “model”
RDMs, in our case the pixel and FaceNet RDMs. We can also specify labels_rdm_model
to indicate which rows of the model RDMs correspond to which images to make sure the
ordering is the same. mne_rsa.rsa_epochs() will return the RSA scores as a list
of mne.Evoked objects: one for each model RDM we gave it.
We compute the RSA scores for epochs against [pixel_rdm, facenet_rdm] and do
this in a sliding windows across time, with a temporal radius of 0.1 seconds. Setting
verbose=True will activate a progress bar. We can optionally set n_jobs=-1 to
use multiple CPU cores to speed things up.
from mne_rsa import rsa_epochs
ev_rsa = rsa_epochs(
epochs,
[pixel_rdm, facenet_rdm],
labels_epochs=epochs.metadata.file,
labels_rdm_model=filenames,
temporal_radius=0.1,
verbose=True,
n_jobs=-1,
)
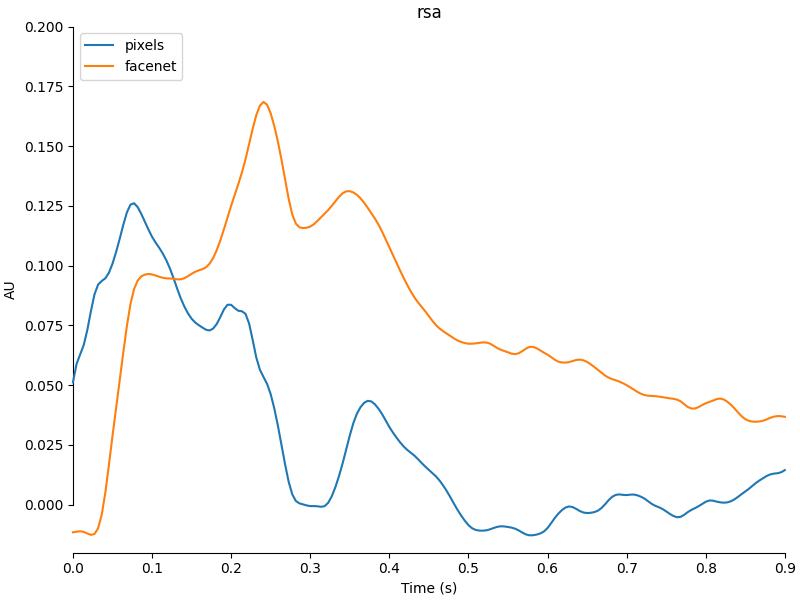
# Create a nice plot of the result
ev_rsa[0].comment = "pixels"
ev_rsa[1].comment = "facenet"
mne.viz.plot_compare_evokeds(
ev_rsa, picks=[0], ylim=dict(misc=[-0.02, 0.2]), show_sensors=False
)
0%| | 0/199 [00:00<?, ?patch/s]
1%|▎ | 1/199 [00:00<00:20, 9.70patch/s]
10%|██████▏ | 20/199 [00:00<00:03, 46.88patch/s]
10%|██████▏ | 20/199 [00:13<00:03, 46.88patch/s]
20%|████████████▎ | 40/199 [00:20<01:36, 1.64patch/s]
30%|██████████████████▍ | 60/199 [00:29<01:15, 1.85patch/s]
40%|████████████████████████▌ | 80/199 [00:32<00:45, 2.59patch/s]
50%|██████████████████████████████▏ | 100/199 [00:35<00:29, 3.41patch/s]
60%|████████████████████████████████████▏ | 120/199 [00:37<00:17, 4.52patch/s]
70%|██████████████████████████████████████████▏ | 140/199 [00:39<00:10, 5.57patch/s]
80%|████████████████████████████████████████████████▏ | 160/199 [00:40<00:05, 6.83patch/s]
90%|██████████████████████████████████████████████████████▎ | 180/199 [00:42<00:02, 8.01patch/s]
100%|████████████████████████████████████████████████████████████| 199/199 [00:42<00:00, 4.73patch/s]
[<Figure size 800x600 with 1 Axes>]
We see that first, the “pixels” representation is the better match to the representation in the brain, but after around 150 ms the representation produced by the FaceNet model matches better. The best match between the brain and FaceNet is found at around 250 ms.
If you’ve made it this far, you have successfully completed your first sensor-level RSA! 🎉 This is the end of this tutorial. I invite you to join me in the next tutorial where we will do source level RSA: Tutorial part 2: RSA on source-level MEG data
Total running time of the script: (2 minutes 8.721 seconds)