Note
Go to the end to download the full example code.
Construct a model RDM#
This example shows how to create RDMs from arbitrary data. A common use case for this is to construct a “model” RDM to RSA against the brain data. In this example, we will create a RDM based on the length of the words shown during an EEG experiment.
Authors#
Marijn van Vliet <marijn.vanvliet@aalto.fi> Stefan Appelhoff <stefan.appelhoff@mailbox.org>
# Import required packages
import mne
import mne_rsa
MNE-Python contains a build-in data loader for the kiloword dataset, which is used
here as an example dataset. Since we only need the words shown during the experiment,
which are in the metadata, we can pass preload=False to prevent MNE-Python from
loading the EEG data, which is a nice speed gain.
data_path = mne.datasets.kiloword.data_path(verbose=True)
epochs = mne.read_epochs(data_path / "kword_metadata-epo.fif", preload=False)
# Show the metadata of 10 random epochs
print(epochs.metadata.sample(10))
Reading C:\Users\wmvan\mne_data\MNE-kiloword-data\kword_metadata-epo.fif ...
Isotrak not found
Found the data of interest:
t = -100.00 ... 920.00 ms
0 CTF compensation matrices available
Adding metadata with 8 columns
960 matching events found
No baseline correction applied
0 projection items activated
WORD Concreteness WordFrequency ... BigramFrequency ConsonantVowelProportion VisualComplexity
458 monument 5.60 2.278754 ... 611.000000 0.625000 72.044648
897 mistake 3.40 2.928396 ... 674.000000 0.571429 68.146539
674 research 4.05 3.334856 ... 636.375000 0.625000 65.317730
592 notion 2.30 2.815578 ... 459.166667 0.500000 59.229152
123 camera 6.20 2.635484 ... 941.166667 0.500000 71.909491
807 plaza 5.70 1.792392 ... 326.600000 0.600000 67.873974
241 hope 1.75 3.009451 ... 419.000000 0.500000 76.603193
216 appetite 3.85 2.536558 ... 548.500000 0.500000 67.873615
912 function 3.30 2.998695 ... 491.875000 0.625000 57.562123
638 contact 4.00 3.077368 ... 1042.428571 0.714286 61.307924
[10 rows x 8 columns]
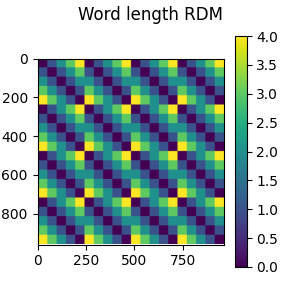
Now we are ready to create the “model” RDM, which will encode the difference in length between the words shown during the experiment.
rdm = mne_rsa.compute_rdm(epochs.metadata.NumberOfLetters, metric="euclidean")
# Plot the RDM
fig = mne_rsa.plot_rdms(rdm, title="Word length RDM")
fig.set_size_inches(3, 3) # Make figure a little bigger to show axis properly
Total running time of the script: (0 minutes 0.972 seconds)